Зависимость урожайности от вида удобрений
На опытном участке проверялась зависимость урожая культуры одного и того же сорта от внесения различных удобрений. Первая грядка контрольная(control), растения во второй подкармливались только органическим удобрением (organic), растения третьей грядки подкармливались универсальным удобрением (universal) и наконец растения четвертой грядки подкармливались комплексным удобрением (complex). В файле urozaj (загрузить файл urozaj с нашего сайта) представлены данные об измерениях массы плодов культуры и типа применяемого для подкормки удобрения. Необходимо проанализировать данные и выяснить какие типы удобрений максимально эффективно влияют на урожайность культуры. Сначала загрузим файл предварительно скопировав его в рабочую директорию, а затем пропишем в скрипте путь к загруженному файлу:
setwd('C:/datas/')
data = read.csv(file = "urozaj.csv",header = T)
data = data[2:3]
head(data)
str(data)
| > head(data) massa name 1 59.10 control 2 57.89 control 3 54.13 control 4 58.33 control 5 46.73 control 6 50.03 control > str(data) 'data.frame': 450 obs. of 2 variables: $ massa: num 59.1 57.9 54.1 58.3 46.7 ... $ name : chr "control" "control" "control" "control" ... |
Предварительный анализ датасета показал, что в нем содержаться числовые и строковые данные. Для более удобной работы (и чтобы раскрыть все возможности среды программирования R) произведем замену строковой переменной на факторы:
data$name = as.factor(data$name)
str(data)
| > str(data) 'data.frame': 450 obs. of 2 variables: $ massa: num 59.1 57.9 54.1 58.3 46.7 ... $ name : Factor w/ 4 levels "complex","control",..: 2 2 2 2 2 2 2 2 2 2 ... |
Убедились, что замена прошла успешно и теперь у нас появилась факторная переменная с четырьмя уровнями, которые отображают тип применяемого для подкормки культуры удобрения. Приступим к детальному анализу данных в датасете urozaj. Для начала подсчитаем число наблюдений в каждой группе:
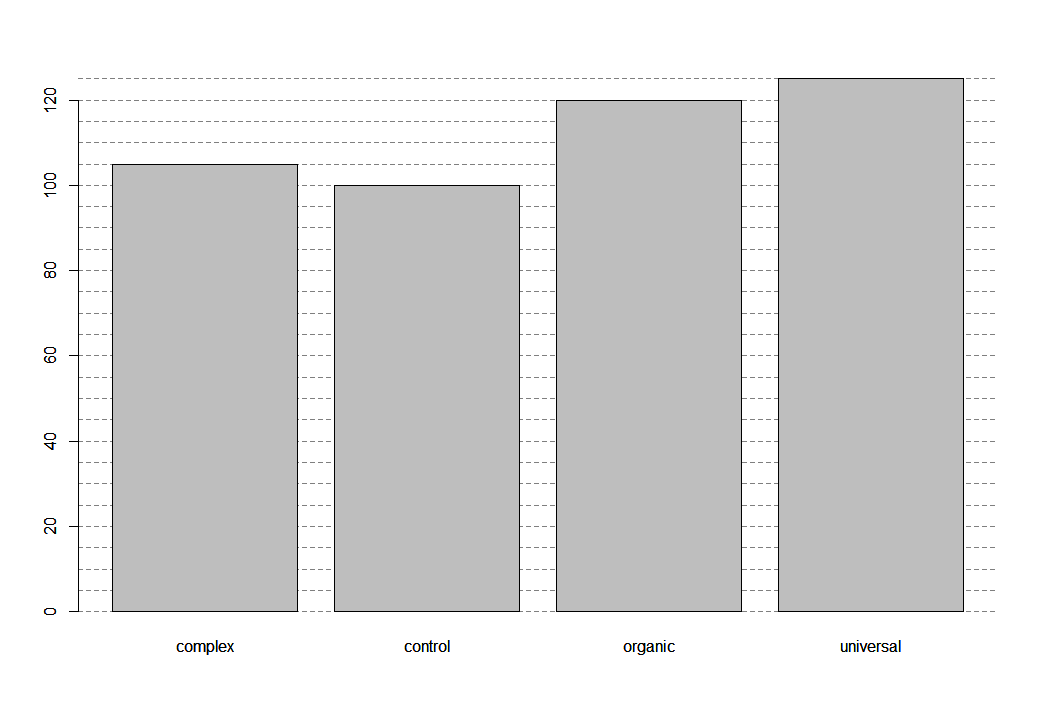
tapply(data$massa,data$name, length)
> tapply(data$massa,data$name, length) complex control organic universal 105 100 120 125 |
для еще большей наглядности отобразим данные на диаграмме
plot(data$name)
# Horizontal grid
abline(h = seq(0, 125, 5),
lty = 2, col = "gray50")
plot(data$name, add=T)
boxplot(massa~name,data)
Проанализируем средние значения по каждой грядке (или по каждому фактору), это удобно представить в виде сравнения в табличной форме. Выполним конструкцию:
cat('Среднее значение урожайности')
tapply(data$massa, data$name, mean)
> tapply(data$massa, data$name, mean) complex control organic universal 51.83267 50.16450 50.15208 51.05232 |
Если в формуле заменить mean на sd то получим дополнительно еще и отчет по стандартному отклонению в каждой группе.
tapply(data$massa, data$name, sd)
> tapply(data$massa, data$name, sd) complex control organic universal 4.003952 4.748208 4.175305 2.948610 |
Так же очень наглядно провести сравнение групп используя «ящик с усами», для чего выполним приведенную ниже конструкцию:
boxplot(massa~name,data)
# Horizontal grid
abline(h = seq(35, 65, 1),
lty = 2, col = "gray50")
boxplot(massa ~ name,data, add=T, lwd=2)
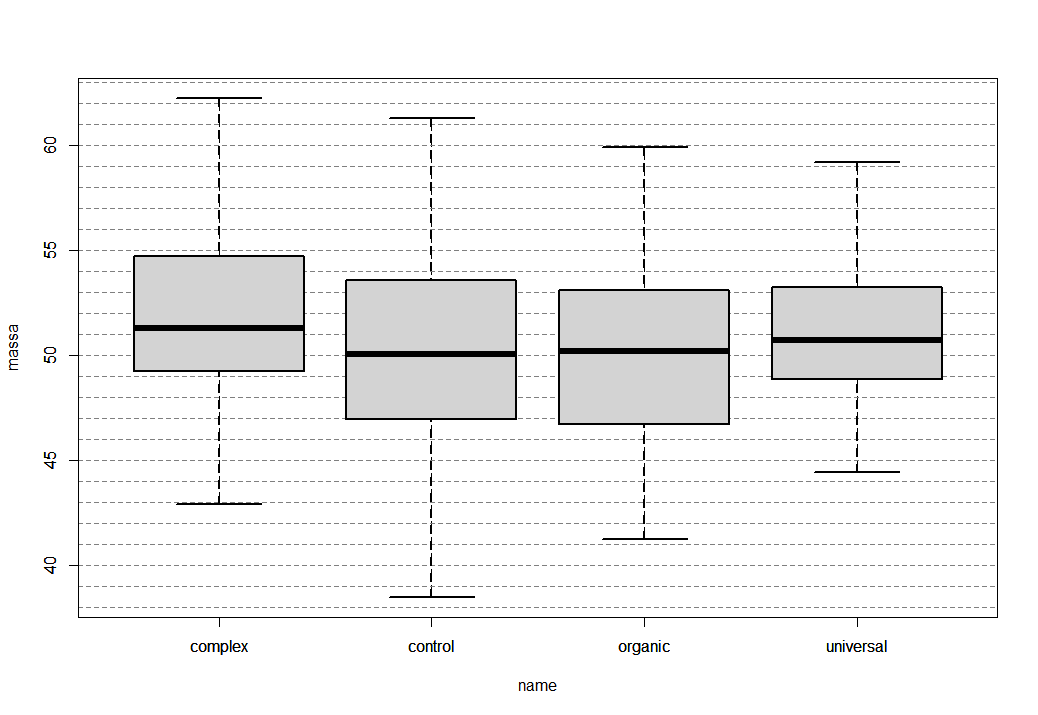
Вот это действительно очень наглядное отображение отличий в группах. Теперь нужно выяснить для начала вообще являются эти различия (по крайней мере хотя бы одно) статистически значимы. Когда у нас есть более двух групп для сравнения, применяется анализ дисперсии (ANOVA). ANOVA позволяет определить, есть ли статистически значимые различия между средними значениями в нескольких группах. В R для проведения ANOVA используется функция aov().
fit = aov(massa ~ name, data)
summary(fit)
> fit = aov(massa ~ name,data) > summary(fit) Df Sum Sq Mean Sq F value Pr(>F) name 3 211 70.23 4.442 0.00433 ** Residuals 446 7052 15.81 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 |
Результат анализа включает в себя информацию о F-статистике, p-значении и межгрупповой дисперсии. Если p-значение ниже заданного уровня значимости (обычно 0.05), то мы можем отвергнуть нулевую гипотезу о равенстве средних значений. В нашем случае p-значение равно 0.00433 ** это намного ниже уровня значимости 0.05, и мы отвергаем нулевую гипотезу: различия в группах (по крайней мере хотя бы в одной из них) статистически значимы. Осталось выяснить какие группы или хотя бы одна из них статичстически значимо отличается. Для этого проведем еще один тест, выполнив конструкцию:
TukeyHSD(fit)
> TukeyHSD(fit) Tukey multiple comparisons of means 95% family-wise confidence level Fit: aov(formula = massa ~ name, data = data) $name diff lwr upr p adj control-complex -1.66816667 -3.1009382 -0.2353952 0.0149611 organic-complex -1.68058333 -3.0508360 -0.3103307 0.0090279 universal-complex -0.78034667 -2.1377500 0.5770567 0.4489572 organic-control -0.01241667 -1.4008191 1.3759858 0.9999956 universal-control 0.88782000 -0.4879027 2.2635427 0.3439842 universal-organic 0.90023667 -0.4102484 2.2107217 0.2884956 |
Самое сильное различие в "control-complex" p = 0.0149611, что подтверждает сильное влияние подкормки комплексным удобрением на урожайность. Так же значимо влияет на увеличение урожая и органическое удобрение "organic-complex" хотя и немного в меньшей степени, здесь значение p = 0.0090279. В остальных парных сравнениях статистически значимых отличий нет ( p больше уровня значимости 0.05). Добавим к отчету еще один график на котором отобразим средние значения точками и добавим доверительные интервалы:
library(ggplot2)
ggplot(data, aes(name, massa))+
stat_summary(fun.data = mean_cl_boot, geom = "errorbar", width = 0.1, size = 1)+
stat_summary(fun.y = mean, geom = "point", size = 6, shape = 22, fill = "white")+
theme_bw()+
xlab("Вид удобрений")+
ylab("Урожайность")
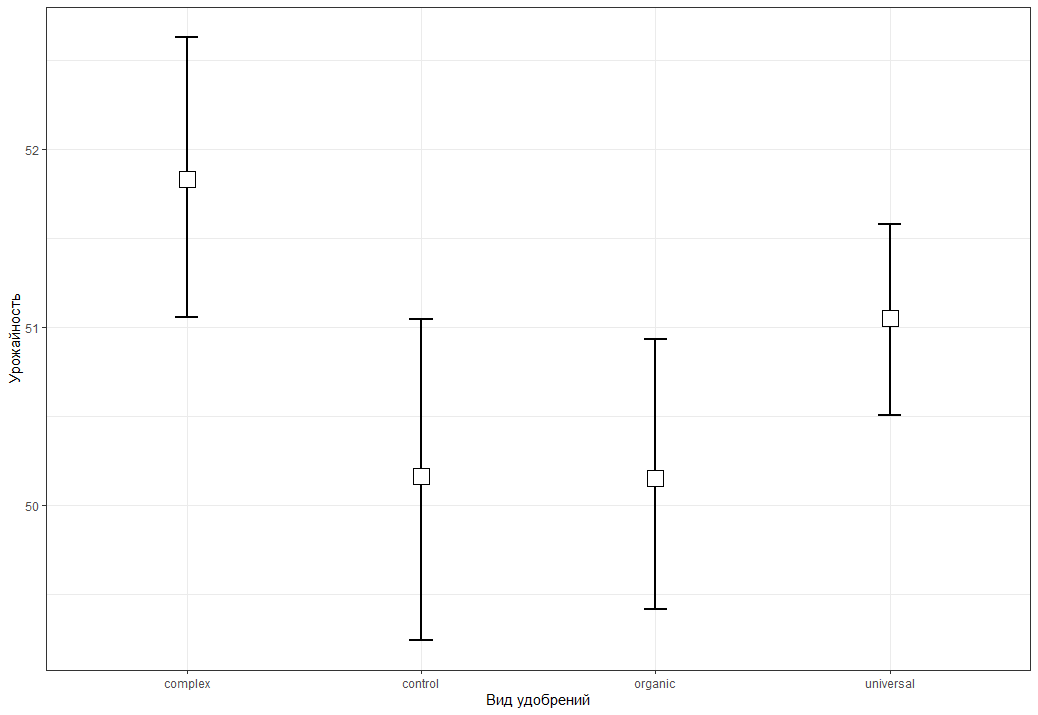
Непересекающиеся доверительные интервалы подтверждают наш вывод о статистически значимых различиях в контрольной грядке и в грядке где культуру подкармливали комплексным удобрением. Исходя из всех полученных данных окончательно приходим к выводу: только комплексное удобрение способствовало значимому повышения урожайности (в сравнении с контрольной грядкой). В завершении проведем еще тест на различия между контрольной группой и грядками где культуры подкармливались комплексным и универсальным удобрением (нас интересует значение p для каждой из сравниваемых групп: в случае когда доверительные интервалы не пересекаются (то есть есть значимые различия) и наоборот когда они пересекаются.
contrl = data$massa[data$name=='control']
complex = data$massa[data$name=='complex']
universal = data$massa[data$name=='universal']
t.test(contrl, complex)
t.test(contrl, universal)
> t.test(contrl, complex) Welch Two Sample t-test data: contrl and complex t = -2.7128, df = 193.86, p-value = 0.007273 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -2.8809756 -0.4553578 sample estimates: mean of x mean of y 50.16450 51.83267 > universal = data$massa[data$name=='universal'] > t.test(contrl, universal) Welch Two Sample t-test data: contrl and universal t = -1.6346, df = 157.54, p-value = 0.1041 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -1.9606107 0.1849707 sample estimates: mean of x mean of y 50.16450 51.05232 |
Собственно что и требовалось доказать. Привожу по традиции полный скрипт ( загрузить скрипт урожай с сервера) проведенного выше анализа датасета.
|
setwd('C:/datas/') data = read.csv(file = "urozaj.csv",header = T) plot(data$name) cat('Среднее значение урожайности') fit = aov(massa ~ name,data) library(ggplot2) contrl = data$massa[data$name=='control'] |