Нормированное отклонение
Нормированное отклонение (или Z – показатель) – мера относительного разброса наблюдаемого или измеренного значения, которая показывает, сколько стандартных отклонений составляет его разброс относительно среднего значения. Иными словами, с помощью этой метрики можно сравнивать отдельные значения со средним. Для вычисления Z – оценки используется следующая формула
Z = (Xi – Xср)/SD. Где,
Z – нормированное отклонение (Z – показатель)
Xi – отдельная варианта в выборке
Xср – среднее значение по выборке
SD – стандартное отклонение по выборке
Отрицательные z-показатель означают, что значение меньше среднего, положительный, что больше среднего. Среднее значение нормированного отклонения всегда равно 0, а стандартное отклонение нормированных отклонений всегда равно 1.В чём бы ни измерялась переменная, среднее значение ее нормированных отклонений всегда равно 0, а стандартное отклонение нормированных отклонений всегда равно 1. Благодаря этим свойствам z-показатель может использоваться для сравнения значений, имеющих разный размах (разность между максимальным и минимальным значениями) и разные единицы измерения.
Задача 1. Сгенерируйте 500 СЧ НР с mean = 20, sd = 15, округлив их до одного знака после запятой. Создайте таблицу данных с двумя колонками: варианты и нормированные отклонения. Выведите только те строки таблицы, у которых нормированное отклонение превышает 2.
set.seed(5)
a = round(rnorm(500, 20, 15),1)
Xcp = mean(a)
SD = sd(a)
Z = (a - Xcp)/SD
dt = data.frame(Xi = a, Z)
dt[dt$Z > 2,]
| > dt[dt$Z > 2,] Xi Z 33 53.2 2.205215 87 55.8 2.377491 113 59.0 2.589523 143 52.7 2.172084 162 53.7 2.238345 181 52.7 2.172084 223 50.4 2.019686 266 53.0 2.191963 362 50.4 2.019686 381 51.7 2.105824 416 53.7 2.238345 |
Задача 2. Сгенерируйте выборку из 1000 чисел НР с mean = 200, sd = 5. Известно, что при нормальном распределении 68% данных находится в интервале плюс-минус одно стандартное отклонение от среднего. Проверьте это на практике подсчитав количество всех чисел, находящихся в интервале плюс-минус, одна сигма. Результат округлите до одной десятой. Повторите генерацию выборки увеличив число до 10000 и 100000. Результаты сравните и сделайте вывод.
(Ответ: 1000 = 69.6, 10000 = 68.79, 100000 = 68.159. При генерации выборки в 10000 чисел получили наиболее точный результат: 68.2 %).
set.seed(5)
N = 1000
a = round(rnorm(N, 200, 5),1)
Xcp = mean(a)
SD = sd(a)
Z = (a - Xcp)/SD
dt = data.frame(Xi = a, Z)
head(dt)
b = dt[abs(dt$Z) > 0 & abs(dt$Z) <= 1,]
length(b$Xi)/N*100
| > length(b$Xi)/N*100 [1] 69.6 |
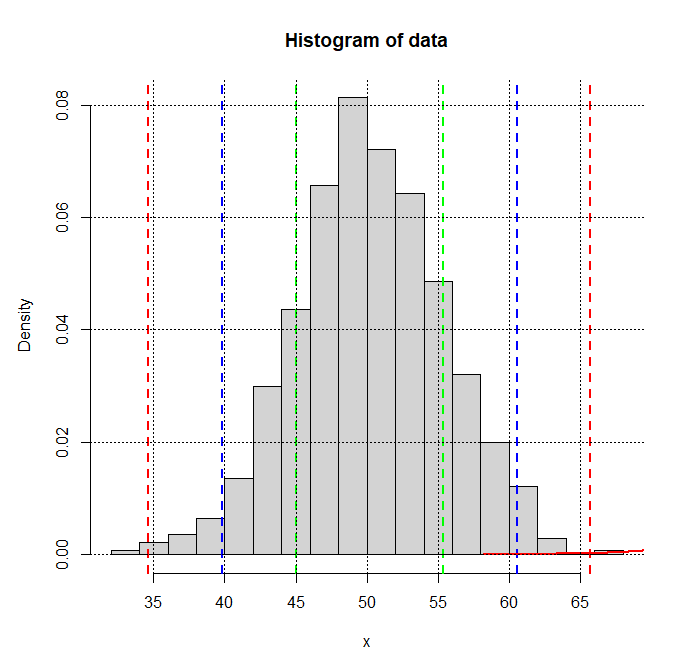
Задача 3. Сгенерируйте 700 чисел НР с mean = 50, sd = 5. Постройте гистограмму, график плотности нормального распределения. Также добавьте пунктирные вертикальные линии нормированных отклонений обозначив их разным цветом (1 зеленая, 2 синяя и 3 красная). Обратите внимание на данные находящихся за пределами 3 сигмы. Выведите эти данные в консоль.
set.seed(5)
x = rnorm(700, 50, 5)
# freq = FALSE - обязательно, так как нужны не абсолютные частоты, а нормализованные
hist(x, main = "Histogram of data", freq = FALSE,20)
# na.rm = TRUE - не учитываем пропуски (NA)
# lwd - line width, толщина линии
curve(dnorm(x, mean = 50, sd = 5), xlim = c(20, 80),
lwd = 2, add = TRUE)
# границы нормир откл
# 1 зеленый, 2 синий, 3 красный
Xsr = mean(x)
Sx = sd(x)
t1p = 1*Sx + Xsr
t1n = -1*Sx + Xsr
abline(v = t1n, lty =2, lwd=2, col='green')
abline(v = t1p, lty =2, lwd=2, col='green')
t2p = 2*Sx + Xsr
t2n = -2*Sx + Xsr
abline(v = t2n, lty =2, lwd=2, col='blue')
abline(v = t2p, lty =2, lwd=2, col='blue')
t3p = 3*Sx + Xsr
t3n = -3*Sx + Xsr
abline(v = t3n, lty =2, lwd=2, col='red')
abline(v = t3p, lty =2, lwd=2, col='red')
z = (x - Xsr)/Sx
dt = data.frame(x, z)
dt[abs(dt$z) >= 3,"x"]
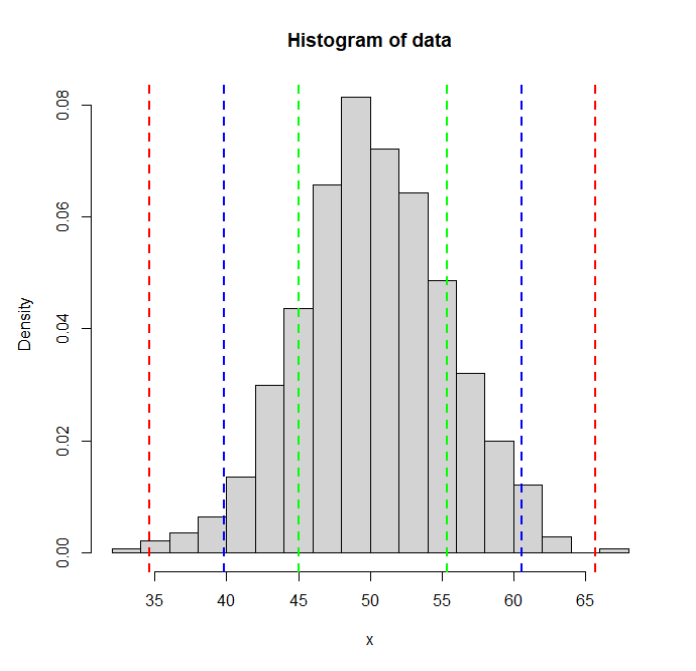
| > dt[abs(dt$z) >= 3,"x"] [1] 32.50971 67.00936 |
Задача 4. Создайте модель Генеральной Совокупности 3000 чисел НР с mean = 100, sd = 10. Постройте гистограмму с кривой плотности вероятности для данной ГС. Подсчитайте количество элементов ГС в интервале от 110 до 120 тремя разными способами. Указание к решению задачи (воспользуйтесь функцией pnorm в качестве первого способа, непосредственным подсчетом чисел в векторе ГС по заданным логическим условиям в качестве второго способа. Третий способ решения проинтегрировать функцию плотности вероятности в заданном интервале). Сравните полученные значения между собой, сделайте вывод. (ответ 408, 416, 408)
set.seed(5)
N = 3000; Mean = 100; SD = 10
Xg = rnorm(N, Mean, SD)
hist(Xg, breaks = 50, freq = F,
xlab = "Vars x",
ylab = "плотность вероятности",
main = "гистограмма с кривой плотности вероятности")
lines(density(Xg),col="red", lwd=2)
grid(col='black')
# число элементов ГС в интервале 110 - 120
points(110,0, lwd=2)
points(120,0, lwd=2)
abline(v = 110, lwd=2)
abline(v = 120, lwd=2)
# первый способ решения
a = pnorm(110, Mean, SD, lower.tail = F)
b = pnorm(120, Mean, SD, lower.tail = F)
round((a-b)*N)
# второй спсоб
Xgfiletr = Xg[(Xg>=110) & (Xg<=120)]
length(Xgfiletr)
# третий способ интеграл
s = integrate(function(Xg) dnorm(Xg, mean = Mean, sd = SD), 110, 120)
round(s$value * N)
| > round(s$value * N) [1] 408 |
Задача 5. Сгенерируйте 10000 чисел НР с mean = 0, sd = 1. Постройте гистограмму, график плотности нормального распределения. Также добавьте пунктирные вертикальные линии нормированных отклонений обозначив их разным цветом (1 зеленая, 2 синяя и 3 красная). Известно, что 13,6 % всех значений лежат в пределах от 1 до 2 σ, напишите скрипт который проверит это утверждение.
set.seed(5)
N = 10000
a = rnorm(N, 0, 1)
hist(a, breaks = 50, freq = F,
xlab = "Vars x",
ylab = "плотность вероятности",
main = "гистограмма с кривой плотности вероятности")
lines(density(a),col="red", lwd=2)
grid(col='black')
Xcp = mean(a)
SD = sd(a)
Z = (a - Xcp)/SD
dt = data.frame(Xi = a, Z)
head(dt)
b = dt[abs(dt$Z) > 0 & abs(dt$Z) <= 1,]
length(b$Xi)/N*100
# границы нормир откл
# 1 зеленый, 2 синий, 3 красный
t1p = 1*SD + Xcp
t1n = -1*SD + Xcp
abline(v = t1n, lty =2, lwd=2, col='green')
abline(v = t1p, lty =2, lwd=2, col='green')
abline(v = Xcp, lwd=2, col='green')
t2p = 2*SD + Xcp
t2n = -2*SD + Xcp
abline(v = t2n, lty =2, lwd=2, col='blue')
abline(v = t2p, lty =2, lwd=2, col='blue')
t3p = 3*SD + Xcp
t3n = -3*SD + Xcp
abline(v = t3n, lty =2, lwd=2, col='red')
abline(v = t3p, lty =2, lwd=2, col='red')
# Правило трех сигм заключается в том, что при нормальном распределении
# практически все значения величины с вероятностью 0,9973
# лежат не далее трех сигм в любую сторону от математического ожидания,
# то есть находятся в диапазоне [μ−3σ;μ+3σ]
# известно что 13,6 % всех значений лежат в пределах от 1 до 2 σ
# проверим так ли это на самом деле
# 1 способ
head(dt)
b12 = dt[dt$Z > 1 & dt$Z <= 2,2]
length(b12)/N*100
# 2 способ
l = pnorm(min(b12), 0, 1, lower.tail = F)
h = pnorm(max(b12), 0, 1, lower.tail = F)
(l-h)*100
# 3 способ
s = integrate(function(a) dnorm(a, mean = 0, sd = 1), min(b12), max(b12))
s$value * 100
b01 = dt[abs(dt$Z) > 0 & abs(dt$Z) <= 1,]
length(b01$Xi)/N*100
Задача 6 интеграл от функции НР
#интеграл от функции НР
Dn = function(x, mn, σ){
1/(σ * sqrt(2 * pi)) * exp(-(x - mn)^2/(2 * σ^2 ))
}
x = seq(0, 3, 0.01)
s = Dn(x, 0, 1)
σ = 1; mn = 0
integrate(function(x) Dn(x, 0, 1), 1, 2)
s = integrate(function(x) 1/(σ * sqrt(2 * pi)) * exp(-(x - mn)^2/(2 * σ^2 )), 1, 2)