ЛР анализ малой выборки
Сначала приведу полный скрипт в котором пошагово проведем статистический анализ небольшой выборки. Для начала загрузите с нашего сайта скрипт Rsummary который поместите папку "R myFunction": C:/R myFunction. Сам скрипт на вход принимает вектор данных
и возвращает (округленные) значения большинства описательных статистик
# Rsummary русифицированный скрипт (функция) на вход принимает вектор
# и возвращает (округленные) значения большинства описательных статистик
setwd('C:/R myFunction')
source('Rsummary.R')
data = c(14.9, 15.7, 18.0, 15.3, 15.9)
Rsummary(x = data)
# hist(data,freq = F)
# lines(density(data), lwd=2, col='red')
#создадим бутстреп выборку из исходных данных
bts = function(data){
n = length(data)
boot = sample(n, replace=TRUE)
data_boot = data[boot]
return(data_boot)
}
Rn = 10
Bdata = as.vector(replicate(Rn, (bts(data = data))))
Rsummary(x = Bdata)
Rsummary(x = data)
# создадим генеральную совокупность
Rn = 5000
Gs = rnorm(Rn, mean(Bdata), sd(Bdata))
Rsummary(Gs)
hist(Gs,freq = F)
lines(density(Gs), lwd=2, col='blue')
abline(v = min(data), lwd = 2, col = 'red')
abline(v = max(data), lwd = 2, col = 'red')
grid(col='black',nx = NA,ny = NULL)
#плотность вероятности в пределах границ измеряемой величины
# Случайная величина X имеет нормальное распределение с
# математическим ожиданием Mean и SD
# Найти вероятность попадания
# этой случайной величины на интервал(min(data) и max(data))
# sd = sqrt(D) # σ = sqrt(D)
abs(pnorm(min(data),mean=Mean,sd=SD)-pnorm(max(data),mean=Mean,sd=SD))
# второй способ интеграл
integrate(function(Gs) dnorm(Gs, mean = Mean, sd = SD), min(data), max(data))
# Calculate the confidence interval
result <- t.test(data,conf.level = 0.95)
# Extract the confidence interval
confidence_interval <- result$conf.int
# Print the confidence interval
confidence_interval
> setwd('C:/R myFunction')
> source('Rsummary.R')
> data = c(14.9, 15.7, 18.0, 15.3, 15.9)
> Rsummary(x = data)
--------------------------------------------------------------------
N Mean SD Disp R Min Max Me CV Cs As Ex
1 5 15.96 1.2 1.45 3.1 14.9 18 15.7 7.54 3.37 0.8 -1.21
|
Выполнив первую часть скрипта (до бутстреп анализа данных, что такое бутстреп можно узнать перейдя по этой ссылке) мы получили описательную статистику исходных данных. Далее с помощью алгоритма бутстрепа мы попытаемся создать модель гораздо большей выборки и затем просто сравним описательные статистики исходных данных с бутсреп выборкой.
|
Следующим шагом создается выборка генеральной совокупности и строится ее гистограмма на которой постараемся максимально наглядно показать анализ нашей выборки графическим способом (одним словом выжать из замечательной среды программирования R максимум возможностей)
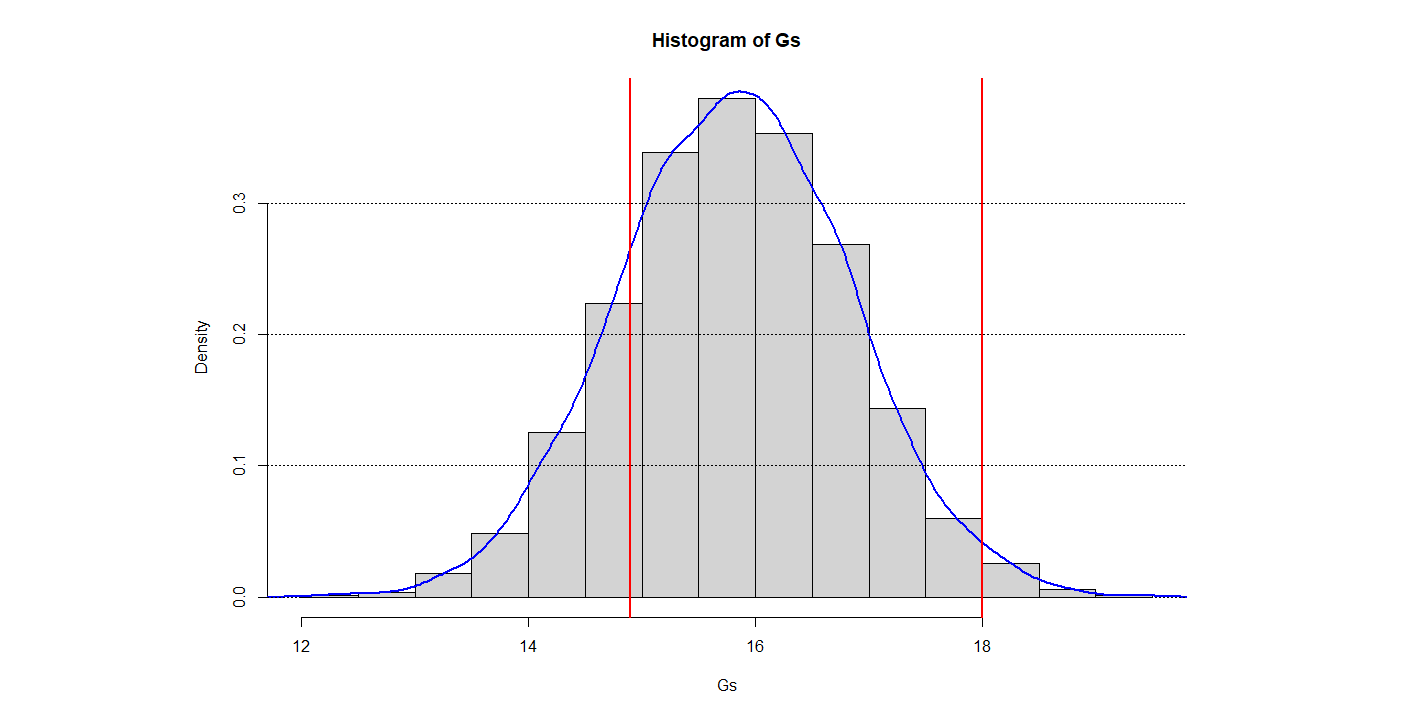
И наконец рассчитаем доверительный интервал
> confidence_interval [1] 14.46587 17.45413 attr(,"conf.level") [1] 0.95 |