Расчет теоретических частот нормального распределения в R
Продемонстрирую как можно в среде программирования R вычислить теоретические частоты нормального распределения. Первым делом сгенерируем выборку нормального распределения целых чисел (это может быть, например размер обуви, одежды и т.п.).
library(rcompanion)
set.seed(454)
N = 120
Mean = 50
SD = 4
siz = round(rnorm(N, Mean, SD))
Далее необходимо проанализировать вектор анализируемых данных (необходимо проверить подчинены ли данные закону нормального распределения). Вообще этот анализ проведем графическим методом (построим гистограмму и график квантилей QQ) а также воспользуемся формальными тестами. Начнем с гистограммы.
plotNormalHistogram(siz, prob = FALSE, col="grey60", border="black",
main = "Normal Distribution overlay on Histogram",
length = 10000, linecol="red", lwd=4 )
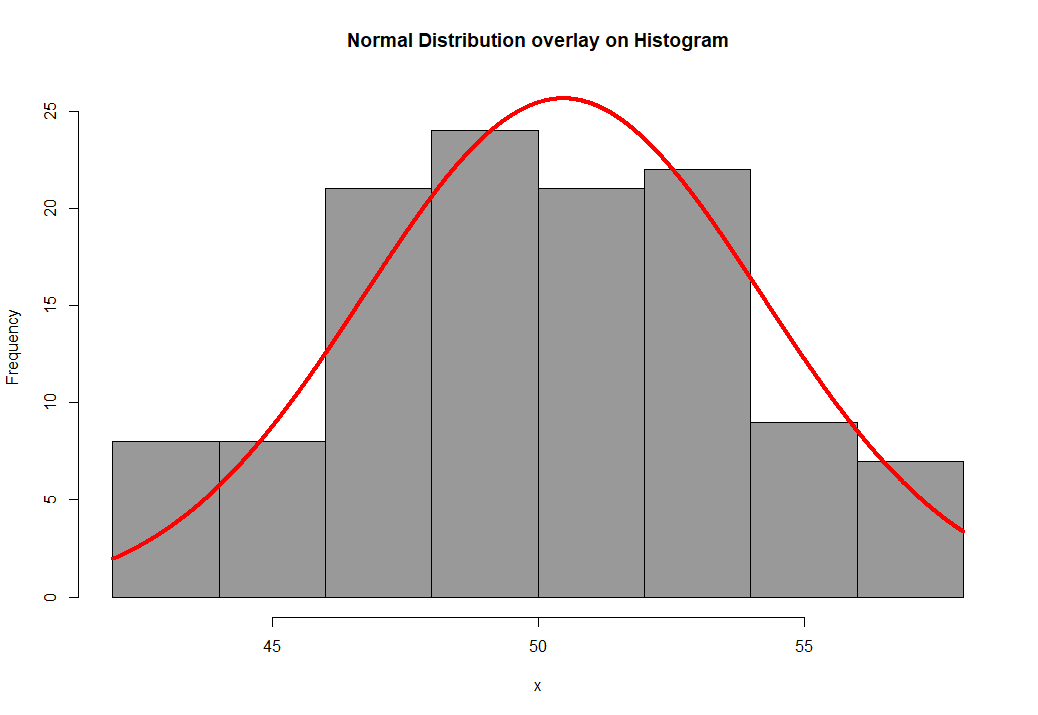
Наглядно видно, что гистограмма напоминает купол нормального распределения (для большей наглядности на нее наложена кривая красного цвета нормального распределения). Однако не всегда можно по гистограмме судить о нормальности распределения данных, особенно в том случае, когда этих данных немного. Поэтому проведем еще один графический QQ тест на нормальность.
# QQтест на нормальное распределение
qqnorm(siz)
qqline(siz, col='red', lwd=2)
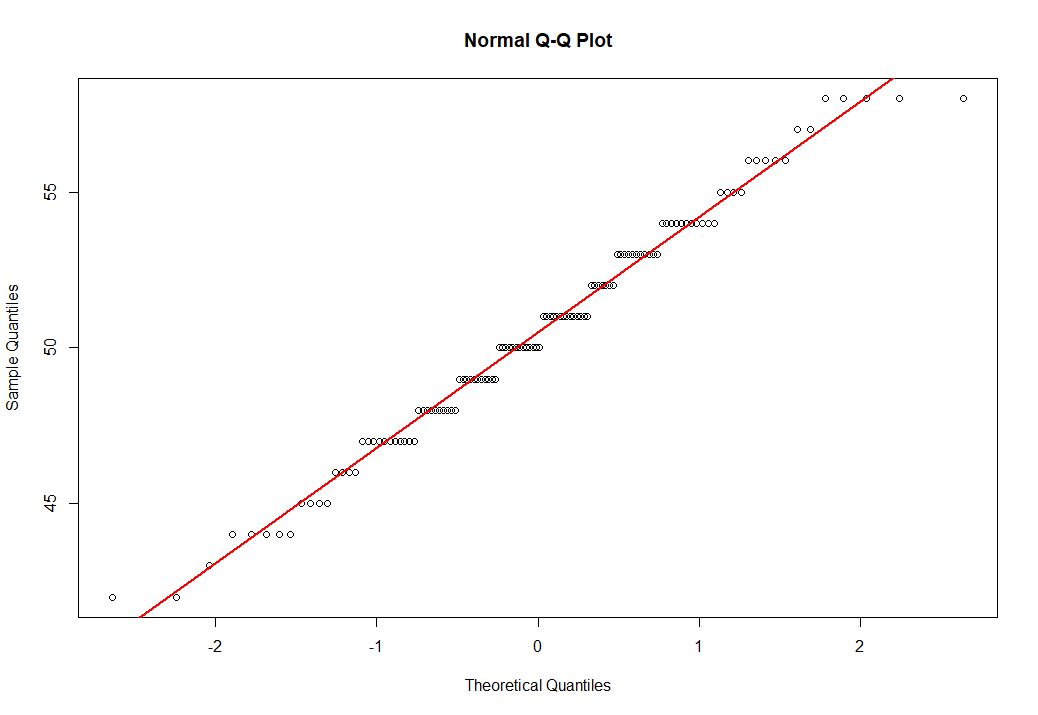
Как видим, QQ тест будет не лишним, и судя по графику мы так же можем с высокой степенью вероятности утверждать, что наши исходные данные в векторе siz действительно подчинены закону нормального распределения, или еще более точнее эти данные принадлежат генеральной совокупности нормального распределения. Так же проведем еще и формальный тест на нормальность.
shapiro.test(siz)
# p-value = 0.168 значительно больше 0.05
# нулевая гипотеза в силе: данные подчинены
# закону нормального распределения
> shapiro.test(siz) Shapiro-Wilk normality test data: siz W = 0.98403, p-value = 0.168 |
После того, как мы убедились, что наши исходные данные принадлежат генеральной совокупности нормального распределения, приступаем ко второму шагу нашей задачи: рассчитаем частоты (в данном случае это будут условные эмпирические частоты исходных данных). Хотя обязательно нужно проверить эти данные на выбросы и при их наличии удалить их (я нарочно опускаю эту часть скрипта «проверка и удаление выбросов из исходных данных» поскольку выбросов в наших данных нет, в других примерах задач выбросы будут удаляться).
tb = table(siz)
|
Итак, мы получили таблицу данных эмпирических частот, и вот наступает последний третий шаг это расчет теоретических частот. Для большей наглядности сделаем таблицу где можно будет наглядно увидеть и сравнить эмпирические и теоретически вычисленные частоты нормального распределения между собой.
dt = as.data.frame(tb)
SIZ = as.vector(dt$sizn)
SIZ = as.numeric(SIZ)
Tfreg = round(dnorm(SIZ, Mean, SD)*N,0)
df = data.frame(dt, Tfreg)
df
sizn Freq Tfreg 1 42 2 2 2 43 1 3 3 44 5 4 4 45 4 5 5 46 4 7 6 47 11 9 7 48 10 11 8 49 11 12 9 50 13 12 10 51 14 12 11 52 7 11 12 53 11 9 13 54 11 7 14 55 4 5 15 56 5 4 16 57 2 3 17 58 5 2 |
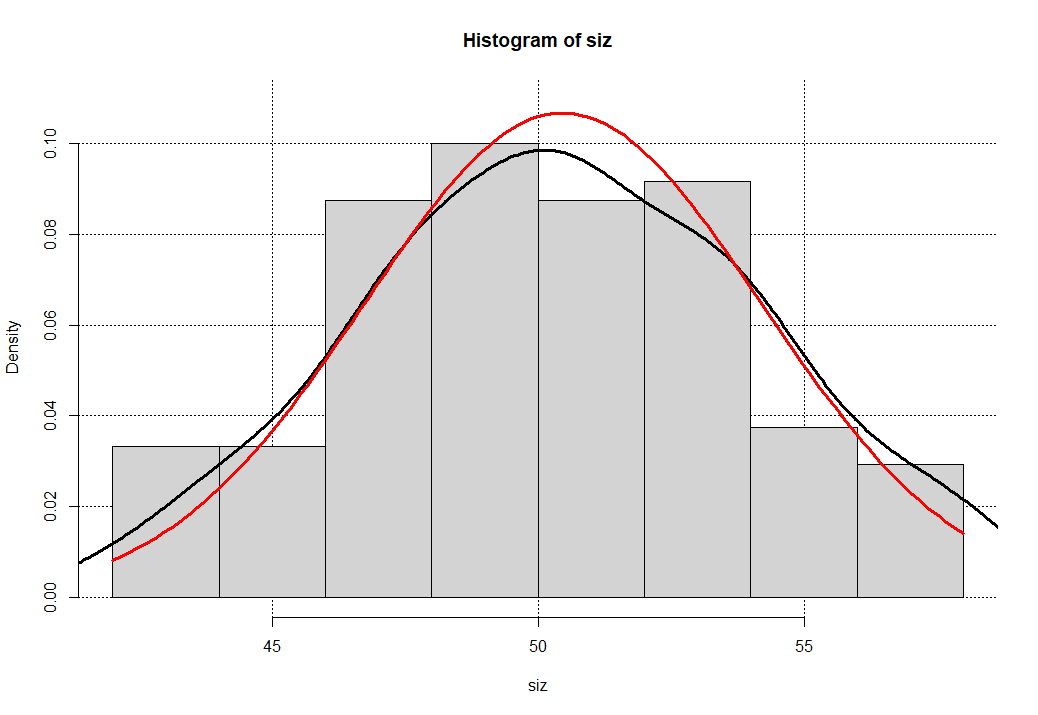
Как видим эмпирические и теоретически вычисленные частоты отлично согласуются между собой и для большей наглядности построим гистограмму с наложенными на нее графиками плотности вероятности и нормального распределения.
Tx <- rep(df$sizn, df$Freq)
Tsiz = as.numeric(as.vector(Tx))
Ylim_max = 0.11
hist(siz,freq = F,ylim = c(0,Ylim_max))
grid(col='black')
Ylim_max = 0.12
hist(siz,freq = F,ylim = c(0,Ylim_max), add=T)
lines(density(siz), lwd = 3 )
curve(dnorm(x, mean = mean(siz), sd = sd(siz)),lwd=3,
col = "red", add = TRUE)