Дисперсионный анализ в R
Настало время перейти от описания выборок к их сравнению, а точнее к оценке статистической значимости различий между ними. Займемся дисперсионным анализом. Дисперсионный анализ применяют для изучения влияния качественных признаков на количественную переменную. В англоязычной литературе он обозначается как ANOVA (Analisis of Variances). Однофакторный дисперсионный анализ используется для определения наличия или отсутствия статистически значимой разницы между средними значениями трех или более независимых групп. Если бы нас вместо этого интересовало влияние двух переменных-предсказателей на переменную отклика, мы могли бы выполнить двусторонний дисперсионный анализ MANOVA (Multiple Analysis of Variance). Это – многомерный дисперсионный анализ, но сейчас мы им заниматься не будем.
Как выполнить односторонний дисперсионный анализ в R ?
Однофакторный дисперсионный анализ используется для определения наличия или отсутствия статистически значимой разницы между средними значениями трех или более независимых групп. Этот тип теста называется однофакторным дисперсионным анализом, поскольку мы анализируем влияние предикторной переменной на переменную отклика.
В качестве примера рассмотрим, как различаются между собой по массе семь различных сортов клубники. Для простоты дадим им названия «сорт1», «сорт2» и т.д. Массы будут сгенерированы случайным образом (нормальное распределение). Эту часть скрипта мы выполним и получим датафрейм всех исходных данных.
# Дисперсионный анализ трех групп
set.seed(5454)
sort1 = round(rnorm(100, 11.6, 3), 1)
sort2 = round(rnorm(120, 11.4, 3.3), 1)
sort3 = round(rnorm(130, 13.4, 2.5), 1)
sort4 = round(rnorm(110, 12.8, 2.4), 1)
sort5 = round(rnorm(150, 11.5, 2.4), 1)
sort6 = round(rnorm(120, 11.1, 2.8), 1)
sort7 = round(rnorm(140, 13.5, 4.4), 1)
df=rbind(data.frame(sort='sort1', massa = sort1),
data.frame(sort='sort2', massa = sort2),
data.frame(sort='sort3', massa = sort3),
data.frame(sort='sort4', massa = sort4),
data.frame(sort='sort5', massa = sort5),
data.frame(sort='sort6', massa = sort6),
data.frame(sort='sort7', massa = sort7))
head(df)
Теперь приступим к изучению полученных искусственно данных. Первое что сделаем – визуализируем эти данные. Выполнив конструкцию ниже мы получим «ящики с усами».
boxplot(massa ~ sort, df)
grid(col='black')
boxplot(massa ~ sort,df,add=T)
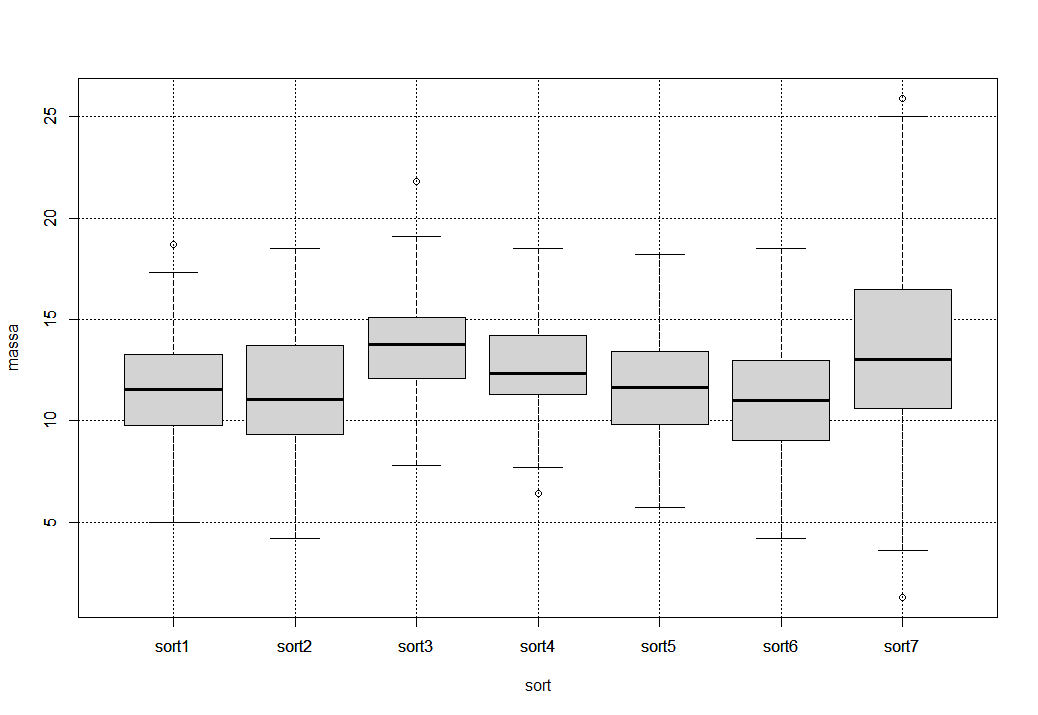
И, собственно, уже что-то не так. А дело в том, что на основании визуализации этих данных мы не можем установить, а есть ли значимые отличия между группами. Максимум что можно увидеть что есть несколько столбиков которые «выделяются» из общей картины. Давайте улучшим исходный вариант следующим образом: отобразим средние значения точками и добавим доверительные интервалы:
library(ggplot2)
ggplot(df, aes(massa, sort))+
stat_summary(fun.data = mean_cl_boot, geom = "errorbar", width = 0.1, size = 1)+
stat_summary(fun.y = mean, geom = "point", size = 6, shape = 22, fill = "white")+
theme_bw()+
xlab("масса граммы")+
ylab("сорта")

Так гораздо лучше! Во-первых, непересекающиеся доверительные интервалы подтверждают наш вывод о статистически значимых различиях. Там где группы статистически различаются доверительные интервалы не пересекаются. Но все же не понятно как сильно различаются группы? Какие группы практически не различаются или напротив различаются максимально сильно. А вот теперь настала очередь применить очень точный и очень серьезный инструмент: собственно дисперсионный анализ.
tmassa = aov(massa ~ sort, df)
summary(tmassa)
ans=TukeyHSD(tmassa)
ans
> ans Tukey multiple comparisons of means 95% family-wise confidence level Fit: aov(formula = massa ~ sort, data = df) $sort diff lwr upr p adj sort2-sort1 -0.25616667 -1.2839968 0.77166345 0.9902972 sort3-sort1 2.11223077 1.1094124 3.11504910 0.0000000 sort4-sort1 1.22027273 0.1636463 2.27689917 0.0119043 sort5-sort1 0.13233333 -0.8291137 1.09378037 0.9996508 sort6-sort1 -0.44866667 -1.4764968 0.57916345 0.8567595 sort7-sort1 2.07728571 1.0964135 3.05815788 0.0000000 sort3-sort2 2.36839744 1.2415641 3.49523074 0.0000000 sort4-sort2 1.47643939 0.3014636 2.65141519 0.0040658 sort5-sort2 0.38850000 -0.7016785 1.47867846 0.9413129 sort6-sort2 -0.19250000 -1.3416490 0.95664900 0.9989214 sort7-sort2 2.33345238 1.2261047 3.44080007 0.0000000 sort4-sort3 -0.89195804 -2.0451180 0.26120196 0.2521003 sort5-sort3 -1.97989744 -3.0465272 -0.91326772 0.0000011 sort6-sort3 -2.56089744 -3.6877307 -1.43406413 0.0000000 sort7-sort3 -0.03494505 -1.1191170 1.04922687 0.9999999 sort5-sort4 -1.08793939 -2.2053085 0.02942974 0.0622145 sort6-sort4 -1.66893939 -2.8439152 -0.49396360 0.0005869 sort7-sort4 0.85701299 -0.2771138 1.99113979 0.2789166 sort6-sort5 -0.58100000 -1.6711785 0.50917846 0.6987057 sort7-sort5 1.94495238 0.8989292 2.99097559 0.0000011 sort7-sort6 2.52595238 1.4186047 3.63330007 0.0000000 |
Данных очень много, но благодаря уникальным возможностям языка программирования R мы можем легко отсортировать эти данные по заданным условиям. Например выведем только данные по тем группам, которые статистически значимо не различаются.
a = as.data.frame(ans$sort)
a[a$`p adj` > 0.05,] #стат значимо не отличаются
> a = as.data.frame(ans$sort) > a[a$`p adj` > 0.05,] #стат значимо не отличаются diff lwr upr p adj sort2-sort1 -0.25616667 -1.2839968 0.77166345 0.99029723 sort5-sort1 0.13233333 -0.8291137 1.09378037 0.99965082 sort6-sort1 -0.44866667 -1.4764968 0.57916345 0.85675954 sort5-sort2 0.38850000 -0.7016785 1.47867846 0.94131285 sort6-sort2 -0.19250000 -1.3416490 0.95664900 0.99892139 sort4-sort3 -0.89195804 -2.0451180 0.26120196 0.25210029 sort7-sort3 -0.03494505 -1.1191170 1.04922687 0.99999994 sort5-sort4 -1.08793939 -2.2053085 0.02942974 0.06221455 sort7-sort4 0.85701299 -0.2771138 1.99113979 0.27891662 sort6-sort5 -0.58100000 -1.6711785 0.50917846 0.69870571 |
Как видим, все теперь наглядно видно и например sort7-sort3 практически не отличаются p adj = 0.99999994. Вспомним что эти данные были сгенерированы с заданными усчловиями искусственно (среднее арифметическое у них : 13.4 и 13.5 соответсвенно)
sort3 = round(rnorm(130, 13.4, 2.5), 1)
sort7 = round(rnorm(140, 13.5, 4.4), 1)
Выведем теперь данные по всем группам, которые имеют статистически значимые различия:
a[a$`p adj` < 0.05,] # есть различия
> a[a$`p adj` < 0.05,] # есть различия diff lwr upr p adj sort3-sort1 2.112231 1.1094124 3.1150491 1.521462e-08 sort4-sort1 1.220273 0.1636463 2.2768992 1.190434e-02 sort7-sort1 2.077286 1.0964135 3.0581579 1.234922e-08 sort3-sort2 2.368397 1.2415641 3.4952307 1.649781e-08 sort4-sort2 1.476439 0.3014636 2.6514152 4.065762e-03 sort7-sort2 2.333452 1.2261047 3.4408001 1.495517e-08 sort5-sort3 -1.979897 -3.0465272 -0.9132677 1.106210e-06 sort6-sort3 -2.560897 -3.6877307 -1.4340641 6.748296e-10 sort6-sort4 -1.668939 -2.8439152 -0.4939636 5.869143e-04 sort7-sort5 1.944952 0.8989292 2.9909756 1.051076e-06 sort7-sort6 2.525952 1.4186047 3.6333001 5.730612e-10 |
Данные можно так же сортировать по заданным условиям, например отберем только те которые p adj будет отличаться больше 1.e-06
a[a$`p adj`<= 1e-07,]
> a[a$`p adj`<= 1e-07,] diff lwr upr p adj sort3-sort1 2.112231 1.109412 3.115049 1.521462e-08 sort7-sort1 2.077286 1.096414 3.058158 1.234922e-08 sort3-sort2 2.368397 1.241564 3.495231 1.649781e-08 sort7-sort2 2.333452 1.226105 3.440800 1.495517e-08 sort6-sort3 -2.560897 -3.687731 -1.434064 6.748296e-10 sort7-sort6 2.525952 1.418605 3.633300 5.730612e-10 |
А теперь давайте выясним, какие группы максимально различаются друг от друга:
a[a$`p adj` == min(a$`p adj`),] # max различаются
> a[a$`p adj` == min(a$`p adj`),] # max различаются diff lwr upr p adj sort7-sort6 2.525952 1.418605 3.6333 5.730612e-10 |
Получили ответ: sort7-sort6 и это действительно так, как их средние значения при генерации максимально различались от остальных групп
sort6 = round(rnorm(120, 11.1, 2.8), 1)
sort7 = round(rnorm(140, 13.5, 4.4), 1)
Полный скрипт ниже:
# Дисперсионный анализ трех групп
set.seed(5454)
sort1 = round(rnorm(100, 11.6, 3), 1)
sort2 = round(rnorm(120, 11.4, 3.3), 1)
sort3 = round(rnorm(130, 13.4, 2.5), 1)
sort4 = round(rnorm(110, 12.8, 2.4), 1)
sort5 = round(rnorm(150, 11.5, 2.4), 1)
sort6 = round(rnorm(120, 11.1, 2.8), 1)
sort7 = round(rnorm(140, 13.5, 4.4), 1)
df=rbind(
data.frame(sort='sort1', massa = sort1),
data.frame(sort='sort2', massa = sort2),
data.frame(sort='sort3', massa = sort3),
data.frame(sort='sort4', massa = sort4),
data.frame(sort='sort5', massa = sort5),
data.frame(sort='sort6', massa = sort6),
data.frame(sort='sort7', massa = sort7))
head(df)
boxplot(massa ~ sort, df)
grid(col='black')
boxplot(massa ~ sort,df,add=T)
tmassa = aov(massa ~ sort, df)
summary(tmassa)
ans=TukeyHSD(tmassa)
ans
a = as.data.frame(ans$sort)
a[a$`p adj` > 0.05,] #стат значимо не отличаются
a[a$`p adj` < 0.05,] # есть различия
a[a$`p adj` == min(a$`p adj`),] # max различаются
a[a$`p adj`<= 1e-07,]
a[a$`p adj` < 0.05,][4,]
a[a$`p adj` == min(a$`p adj`),]
library(ggplot2)
ggplot(df, aes(massa, sort))+
stat_summary(fun.data = mean_cl_boot, geom = "errorbar", width = 0.1, size = 1)+
stat_summary(fun.y = mean, geom = "point", size = 6, shape = 22, fill = "white")+
theme_bw()+
xlab("масса граммы")+
ylab("сорта")