Пример анализа данных в R
Данный материал предназначен для тех, кто хотел бы сразу увидеть практическую работу в среде программирования R, связанная с обработкой и анализом данных. В качестве примера датасета мы загрузим файл с искусственной созданной выборкой о воображаемых жуках, состоящих из четырех столбцов: пол жука (POL: 0-самки, 1-самцы), окрас жуков (CVET: красный=1, синий=2, зеленый=3), масса жука в граммах (VES), и наконец длина жука в миллиметрах (ROST). Данные находятся в файле datab.
Для начала создадим на диске С папку datas, поместим в нее файл datab и укажем в скрипте путь к директории и к самому файлу.
setwd('C:/datas/')
data = read.csv(file = "datab.csv",header = T)
head(data) # отображение первых tail(data, n)
tail(data) # и последних n строк набора
> setwd('C:/datas/')
> data = read.csv(file = "datab.csv",header = T)
> head(data) # отображение первых tail(data, n)
X POL CVET VES ROST
1 1 0 3 78 93
2 2 1 2 28 96
3 3 1 1 42 52
4 4 0 1 31 127
5 5 0 3 56 77
6 6 1 1 44 149
> tail(data) # и последних n строк набора
X POL CVET VES ROST
95 95 0 2 22 133
96 96 1 3 117 142
97 97 1 3 99 77
98 98 1 2 73 97
99 99 1 1 42 55
100 100 1 1 25 104
|
Проанализируем данные и выясним сколько жуков каждого цвета встречаются среди самок и самцов. В результате мы получим таблицу в которой строки - обозначают условные цвета, а столбцы обозначают самок и самцов.
table(data$CVET, data$POL)
> table(data$CVET, data$POL) 0 1 1 15 22 2 13 20 3 19 11 |
Сравним между собой средние массы самок и самцов.
#найдем средние массы у самцов
mean(data[data$POL==1,]$VES)
#найдем средние массы у самок
mean(data[data$POL==0,]$VES)
Но лучше это выполнить одной строкой:
tapply(data$VES, data$POL, mean)
> #найдем средние массы у самцов > mean(data[data$POL==1,]$VES) [1] 68.18868 > #найдем средние массы у самок > mean(data[data$POL==0,]$VES) [1] 74.53191 > tapply(data$VES, data$POL, mean) 0 1 74.53191 68.18868 |
выясним статистическую разницу между средними показателями (для начала напишем длинную и неуклюжую конструкцию, которая вначале создаст два вектора массы самок и самцов а уж только затем проведет статистический тест на различие средних в двух разных группах).
dt1 = data[data$POL==1,]$VES
dt2 = data[data$POL==0,]$VES
t.test(dt1, dt2)
Значение p-value = 0.2741, а это означает что у нас нет никаких оснований отклонить нулевую гипотезу, которая утверждает, что в сравниваемых группах нет значимых статистических отличий, а различия носят всего лишь случайный характер. А теперь получим тот же результат, но используя компактную запись.
t.test(data$VES ~ data$POL)
> t.test(data$VES ~ data$POL) Welch Two Sample t-test data: data$VES by data$POL t = 1.0998, df = 97.543, p-value = 0.2741 alternative hypothesis: true difference in means between group 0 and group 1 is not equal to 0 95 percent confidence interval: -5.103236 17.789708 sample estimates: mean in group 0 mean in group 1 74.53191 68.18868 |
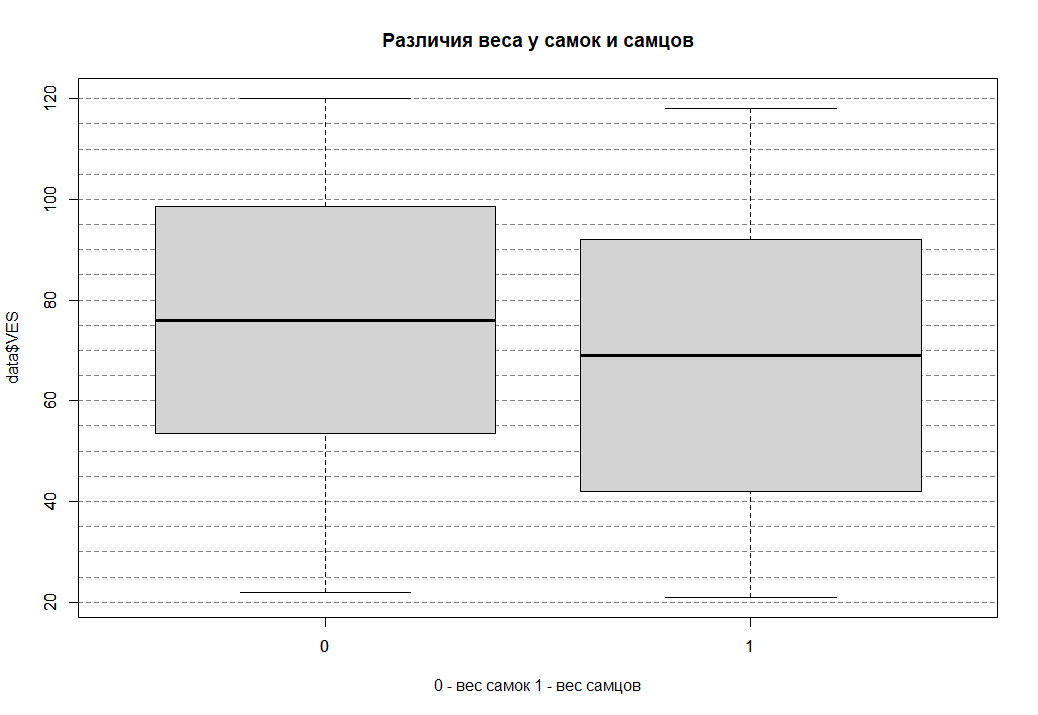
Для наглядности построим ящик с усами, где и сравним одновременно две группы между собой. Сначала поострим ящик с усами и необходимыми пояснениями (заголовок и ось ОХ), далее нанесем сетку (правда она ляжет поверх ящика с усами, поэтому в конце построим ящик с усами еще раз, и тогда сетка окажется под ним).
# boxplot(значения ~ группа, данные)
boxplot(data$VES ~ data$POL, data = data,
main = "Различия веса у самок и самцов",
xlab ='0 - вес самок 1 - вес самцов' )
# Horizontal grid
abline(h = seq(0, 120, 5),
lty = 2, col = "gray50")
boxplot(data$VES ~ data$POL, data = data ,add = T)
Для тех, кто еще не разобрался с импортом данных в среду R из файла, можно создать датафрейм с данными:
N = 100
data <- data.frame(POL = sample(0:1, N, replace = TRUE),
CVET = sample(1:3, N, replace = TRUE),
VES = sample(20:120, N, replace = TRUE),
ROST = sample(50:150, N, replace = TRUE))