Сравнение двух групп
Постановка задачи
В нашем распоряжении имеются данные по определенному количественному показателю (например данные по массе, росту, размеру обуви, и т.п.) в двух группах (группы отличаются, например по сорту, классу, и другими качественными показателями). Наша задача выяснить отличаются ли значения (например, описательной статистики) в этих группах
Примеры
Определить, правда ли, что средний балл по иностранному языку у девочек выше, чем у мальчиков; проверить, действительно ли скорость реакции у людей, которые водят машину, отличается от скорости реакции людей, которые машину не водят.
Методы для сравнения
- t-критерий Стьюдента для двух выборок (two sample Student’s t-test);
- критерий Уилкоксона (Wilcoxon test).
- T-критерий Стьюдента (t-тест Стьюдента)
Применение
Используется, когда распределение исследуемого количественного показателя является нормальным в обеих группах (в каждой из групп). Нулевая и альтернативная гипотезы, которая проверяется с помощью данного критерия:
H0: μ1=μ2 (средние равны, нет различий)
Возможные альтернативные гипотезы:
H1: μ1≠μ2 или H1: μ1<μ2 или H1: μ1>μ2
Под средними значениями в гипотезах подразумеваются средние значения генеральных совокупностей, то есть средние значения показателя «вообще», а не для двух конкретных выборок.
Реализация T-критерия в R:
T-test с неравными дисперсиями t.test(dat$x ~ dat$group)
T-test с неравными дисперсиями t.test(x1 ~ x2)
T-test с равными дисперсиями t.test(dat$x ~ dat$group, var.equal = TRUE)
T-test с равными дисперсиями t.test(x1 ~ x2, var.equal = TRUE)
Нас интересует p-value:
- Если значение p-value меньше любого конвенционального уровня значимости (0.01, 0.05 и 0.1), гипотезу о равенстве средних отвергаем, средние значения в двух группах не равны, то есть различия в данных группах статистически значимы.
- Если значение p-value больше любого конвенционального уровня значимости (0.01, 0.05 и 0.1), гипотезу о равенстве средних оставляем в силе, то есть средние значения в двух группах равны, а различия в данных группах статистически незначимы.
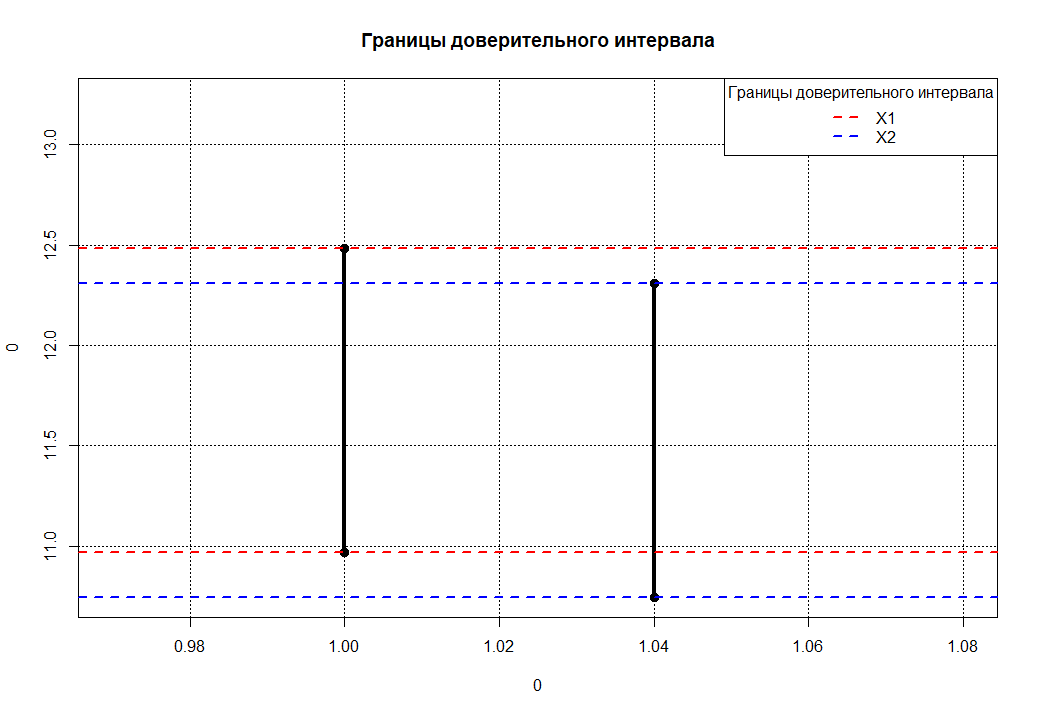
Помимо T-критерия для сравнения различий в двух группах, можно предложить альтернативный метод: сравнение доверительных интервалов в исследуемых группах. При этом, если доверительные интервалы пересекаются в группах, то можно с большей вероятностью предположить, что в группах нет статистически значимых различий. А для наглядности можно построить отрезки доверительных интервалов и выделить их границы (для большей наглядности разными цветами).
Все это легко реализуется в языке R. Ниже привожу скрипт, который для более удобной реализации «обернем» в функцию. На вход функция принимает вектора значений двух групп (с неравными дисперсиями) x1 и x2 и доверительный интервал в процентах CI. Далее функция автоматически проведет расчет описательной статистики (и наглядно выведет ее в виде сводной таблицы), так же будут выведены в виде таблицы сравнения и доверительные интервалы, и отчет по T-test с неравными дисперсиями. И наконец будет автоматически построен график доверительных интервалов. Скрипт 'StatTwoGrupCI.R' в виде функции файл архив можно загрузить с нашего сайта.
setwd('C:/R myFunction')
source('StatTwoGrupCI.R')
options(digits = 4)
set.seed(4545)
x1 = round(rnorm(55, 12, 2))
x2 = round(rnorm(55, 11, 2))
StatTwoGrupCI(x1 = x1, x2 = x2, CI = 99)
> StatTwoGrupCI(x1 = x1, x2 = x2, CI = 99) ----------------------------------------------------- Name N Mean SD Med As Ex Min Max V CS 1 X1 55 11.73 2.103 11 0.22583 -0.91729 8 16 17.94 2.418 2 X2 55 11.53 2.168 12 -0.01497 -0.07168 6 16 18.80 2.535 ----------------------------------------------------- Name Low Hi 1 X1 10.97 12.48 2 X2 10.75 12.31 ----------------------------------------------------- Welch Two Sample t-test data: x1 and x2 t = 0.49, df = 108, p-value = 0.6 alternative hypothesis: true difference in means is not equal to 0 99 percent confidence interval: -0.8679 1.2679 sample estimates: mean of x mean of y 11.73 11.53 |
Текст скрипта:
# описательная статистика по группам
StatTwoGrupCI = function(x1 = x1, x2 = x2, CI = CI){
# Calculate the confidence interval без бутстрепа
CI = CI/100
result1 <- t.test(x1, conf.level = CI)
result2 <- t.test(x2, conf.level = CI)
# Extract the confidence interval
ci1 <- result1$conf.int
ci2 <- result2$conf.int
CI1 = c(ci1[1],ci1[2])
CI2 = c(ci2[1],ci2[2])
CI12 = data.frame(Name = c('X1', 'X2'), Low = c(CI1[1],CI2[1]),
Hi = c(CI1[2],CI2[2]))
#функция графического построения довер интер
y1 = seq(ci1[1],ci1[2], 0.01)
xy1 = rep(1, length(y1))
y2 = seq(ci2[1],ci2[2], 0.01)
xy2 = rep(1.04, length(y2))
y12 = c(y1, y2)
plot(x=0,y=0,col='grey100',
ylim = c(min(y12),(max(y12)+ 0.75)),'l', xlim = c(0.97,1.08),
main='Границы доверительного интервала')
grid(col='black')
lines(xy1, y1,lwd =4)
lines(xy2, y2, lwd=4)
x1min = ci1[1]
x1max = ci1[2]
x2min = ci2[1]
x2max = ci2[2]
points(1,x1min,lwd = 4)
points(1,x1max,lwd = 4)
points(1.04,x2min,lwd = 4)
points(1.04,x2max,lwd = 4)
abline(h = x1min, col='red', lty = "dashed", lwd=2)
abline(h = x1max, col='red', lty = "dashed", lwd=2)
abline(h = x2min, col='blue', lty = "dashed", lwd=2)
abline(h = x2max, col='blue', lty = "dashed", lwd=2)
legend(x = "topright", # Position
legend = c("X1", "X2"), # Legend texts
title = "Границы доверительного интервала", # Title
lty = c(2, 2), # Line types
col = c('red','blue'), # Line colors
lwd = 2) # Line width)
m1 = mean(x1)
med1 = median(x1)
n1 = length(x1)
s1 = sd(x1)
skew1 = sum((x1 - m1)^3/s1^3)/n1
kurt1 = sum((x1 - m1)^4/s1^4)/n1 - 3
minx1 = min(x1)
maxx1 = max(x1)
m2 = mean(x2)
med2 = median(x2)
n2 = length(x2)
s2 = sd(x2)
skew2 = sum((x2 - m2)^3/s2^3)/n2
kurt2 = sum((x2 - m2)^4/s2^4)/n2 - 3
minx2 = min(x2)
maxx2 = max(x2)
v1 = s1/m1*100 # значение коэффициента вариации V %
v2 = s2/m2*100 # значение коэффициента вариации V %
CS1 = v1/sqrt(n1) # показатель точности (CS)
CS2 = v2/sqrt(n2) # показатель точности (CS)
# эксцесс (англ. kurtosis) асимметрия (skewness)
stx12 <<- data.frame(Name = c('X1','X2'),N = c(n1, n2), Mean = c(m1, m2),
SD = c(s1, s2), Med = c(med1, med2),
As = c(skew1, skew2), Ex = c(kurt1, kurt2),
Min = c(minx1, minx2), Max = c(maxx1, maxx2),
V = c(v1, v2), CS= c(CS1, CS2))
cat('-----------------------------------------------------\n')
print(stx12)
cat('-----------------------------------------------------\n')
print(CI12)
cat('-----------------------------------------------------\n')
print(t.test(x1,x2, conf.level = CI))
}