Расчет теоретических частот массы грецких орехов
В 2013 году был собран урожай грецких орехов. В результате случайного отбора из общей массы было отобрано 148 грецких орехов одного сорта. После взвешивания отобранных орехов получили следующие данные (массы указаны в граммах). Необходимо провести анализ данных и построить таблицу эмпирических и теоретических частот.
11.95, 10.95, 12.56, 9.16, 10.08, 10.72, 9.29, 6.15, 5.12, 11.16, 9.51, 10.73, 10.44, 10.10, 10.10, 11.35, 13.05, 12.09, 11.09, 7.86, 5.12, 6.41, 8.76, 10.40, 11.36, 6.07, 11.11, 9.29, 10.25, 11.72, 9.82, 8.07, 9.20, 9.65, 9.87, 12.39, 10.72, 1.84, 9.81, 10.10, 11.04, 10.08, 12.91, 10.30, 12.80, 9.40, 8.65, 10.21, 9.50, 10.97, 11.65, 8.27, 9.90, 9.18, 9.83, 10.41, 10.24, 11.26, 12.37, 9.73, 6.10, 5.84, 12.00, 8.70, 10.15, 10.62, 5.21, 11.34, 9.39, 9.96, 4.80, 10.97, 11.51, 12.44, 11.17, 12.43, 9.41, 10.78, 11.05, 10.85, 10.68, 9.02, 12.37, 10.43, 11.96, 10.93, 10.59, 10.76, 8.27, 9.09, 9.32, 9.36, 10.51, 11.70, 11.76, 10.72, 7.23, 9.34, 9.39, 11.53, 9.85, 10.68, 11.19, 11.29, 10.14, 12.88, 8.85, 10.88, 11.17, 13.30, 10.45, 10.13, 12.07, 10.57, 10.20, 9.74, 8.09, 10.62, 11.12, 13.98, 11.87, 13.48, 11.00, 5.86, 11.24, 10.14, 10.58, 11.04, 9.03, 9.67, 10.73, 10.21, 9.99, 10.98, 5.49, 10.28, 10.70, 13.00, 11.98, 10.04,10.79, 9.65, 10.05, 13.12, 9.41, 4.32, 10.77, 11.40
Решим эту задачу в среде R. Внимание! Скрипт будет обращаться к функции Tndf, которую нужно будет установить в рабочую директорию и указать к ней путь (смотри начало скрипта). Загрузить скрипт функции Tndf.R' с нашего сайта можно кликнув по ссылке.
m3 = c(11.95, 10.95, 12.56, 9.16, 10.08, 10.72, 9.29, 6.15,
5.12, 11.16, 9.51, 10.73, 10.44, 10.10, 10.10, 11.35,
13.05, 12.09, 11.09, 7.86, 5.12, 6.41, 8.76,
10.40, 11.36, 6.07, 11.11, 9.29, 10.25, 11.72,
9.82, 8.07, 9.20, 9.65, 9.87, 12.39, 10.72, 11.84,
9.81, 10.10, 11.04, 10.08, 12.91, 10.30, 12.80,
9.40, 8.65, 10.21, 9.50, 10.97, 11.65, 8.27, 9.90,
9.18, 9.83, 10.41, 10.24, 11.26, 12.37, 9.73, 6.10,
5.84, 12.00, 8.70, 10.15, 10.62, 5.21, 11.34, 9.39,
9.96, 4.80, 10.97, 11.51, 12.44, 11.17, 12.43, 9.41,
10.78, 11.05, 10.85, 10.68, 9.02, 12.37, 10.43,
11.96, 10.93, 10.59, 10.76, 8.27, 9.09, 9.32, 9.36,
10.51, 11.70, 11.76, 10.72, 7.23, 9.34, 9.39, 11.53,
9.85, 10.68, 11.19, 11.29, 10.14, 12.88, 8.85, 10.88,
11.17, 13.30, 10.45, 10.13, 12.07, 10.57, 10.20, 9.74,
8.09, 10.62, 11.12, 13.98, 11.87, 13.48, 11.00, 5.86,
11.24, 10.14, 10.58, 11.04, 9.03, 9.67, 10.73, 10.21,
9.99, 10.98, 5.49, 10.28, 10.70, 13.00, 11.98, 10.04,
10.79, 9.65, 10.05, 13.12, 9.41, 4.32, 10.77, 11.40)
Приступим к анализу полученных данных, и для начала выясним есть ли выбросы в наших данных. Для этого воспользуемся функцией boxplot(m3).
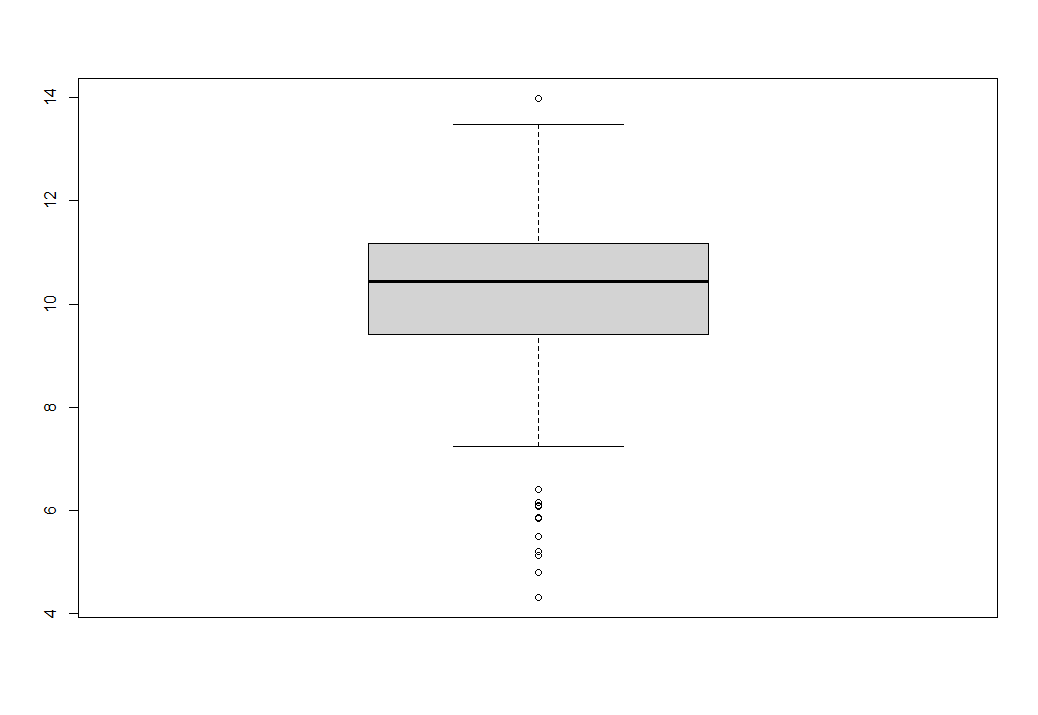
Наглядно видно большое количество данных сильно отклонившихся (они отображаются кружочками). Для удаления выбросов воспользуемся простой конструкцией (параллельно создадим новый вектор без выбросов)
# создадим новый вектор без выбросов m2_n
ind <- which(m3 %in% boxplot.stats(m3)$out)
m3_n <- m3[-ind]
boxplot(m3_n)
Выполнив конструкцию boxplot(m3_n) мы наглядно увидим, как подавляющее большинство выбросов было удалено из первоначального вектора (на оставшиеся два кружочка сверху и снизу можно не обращать внимание). Вторым шагом было бы не лишним выяснить подчиняются оставшиеся данные из нового вектора m3_n (после удаления выбросов из исходного вектора m3) нормальному распределению.
# тест на нормальное распределение
shapiro.test(m3) # m3 c выбросами
shapiro.test(m3_n) # m3_n без выбросами
# p-value = 1.677e-07 (m3) значительно больше 0.05
# p-value = 0.7374 (m3_n) значительно больше 0.05
# нулевая гипотеза в силе: данные подчинены
# закону нормального распределения
# видим что есть небольшой завал слева и немного высоковато
# т.е. As и Ex не равны нулю
# Для нормального распределения коэффициент асимметрии равен нулю,
# а эксцесс — трём. Если эксцесс сильно отличается от трёх,
# то говорят о наличии «тяжёлых хвостов»
#install.packages("moments")
library("moments")
skewness(m3) # коэффициент асимметрии (скошенность)
kurtosis(m3) # эксцесс (пикообразность, крутизна)
skewness(m3_n) # коэффициент асимметрии (скошенность)
kurtosis(m3_n) # эксцесс (пикообразность, крутизна)
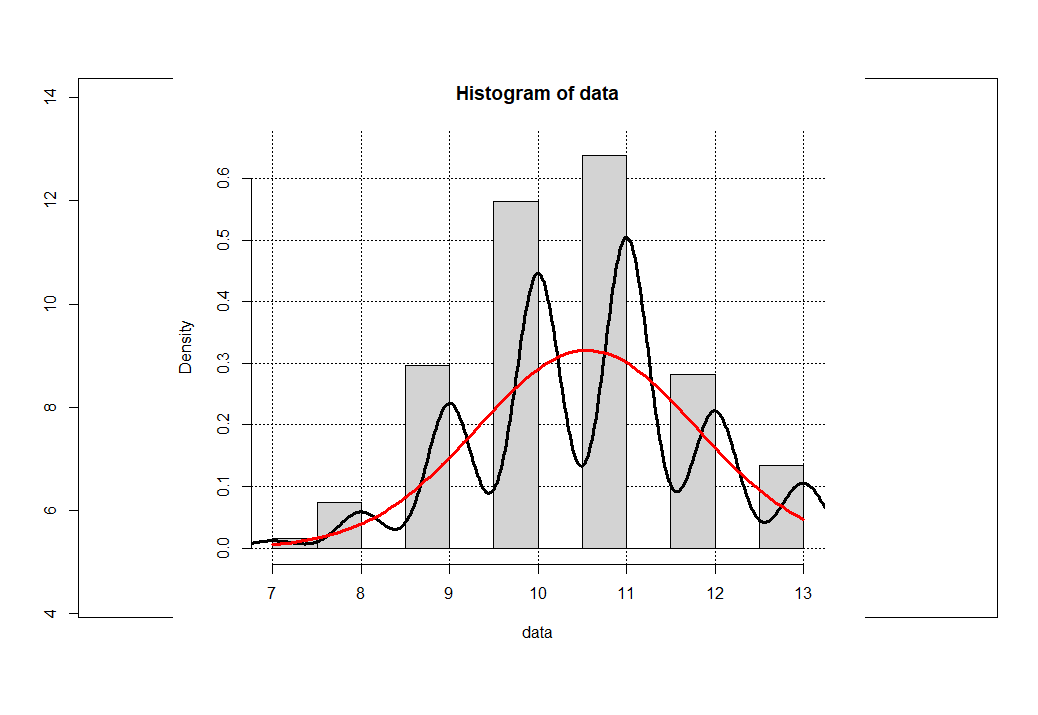
Как видим все тесты наглядно подтверждают, что исходная выборка с выбросами m3_n не прошла тесты на нормальность, и напротив выборка m3_n в которой нет выбросов прошла все тесты на нормальность. Делаем вывод данные в выборке m3_n исходят из генеральной совокупности нормального распределения. Теперь приступим к третьему шагу автоматическому расчёту эмпирических и теоретических частот из вектора данных m3_n. Обратите внимание что функция автоматического расчета теоретических частот из выборки успешно работает с целочисленными значениями, поэтому я предлагаю округлить значения вектора исходных данных до целых чисел : Tndf(data = round(m3_n), Ymax = 0.65)
setwd('C:/R myFunction')
source('Tndf.R')
Tndf(data = round(m3_n), Ymax = 0.65)
sum(DF$Freq)
sum(DF$Tfreg)
sum(DF$ERROR)
> Tndf(data = round(m3_n), Ymax = 0.65) data Freq Tfreg ERROR 1 7 1 1 0 2 8 5 5 0 3 9 20 20 0 4 10 38 39 -1 5 11 43 41 2 6 12 19 22 -3 7 13 9 6 3 > sum(DF$Freq) [1] 135 > sum(DF$Tfreg) [1] 134 > sum(DF$ERROR) [1] 1 |
Осталось проанализировать полученные данные. Датафрейм таблицы эмпирических и теоретических вычисленных частот нормального распределения с ошибкой доступен по имени DF. Как мы наглядно видим эмпирические и теоретические частоты очень хорошо согласовываются между собой.
| data | Freq | Tfreg | ERROR |
| 7 | 1 | 1 | 0 |
| 8 | 5 | 5 | 0 |
| 9 | 20 | 20 | 0 |
| 10 | 38 | 39 | -1 |
| 11 | 43 | 41 | 2 |
| 12 | 19 | 22 | -2 |
| 13 | 9 | 6 | 3 |
Полный скрипт:
m3 = c(11.95, 10.95, 12.56, 9.16, 10.08, 10.72, 9.29, 6.15,
5.12, 11.16, 9.51, 10.73, 10.44, 10.10, 10.10, 11.35,
13.05, 12.09, 11.09, 7.86, 5.12, 6.41, 8.76,
10.40, 11.36, 6.07, 11.11, 9.29, 10.25, 11.72,
9.82, 8.07, 9.20, 9.65, 9.87, 12.39, 10.72, 11.84,
9.81, 10.10, 11.04, 10.08, 12.91, 10.30, 12.80,
9.40, 8.65, 10.21, 9.50, 10.97, 11.65, 8.27, 9.90,
9.18, 9.83, 10.41, 10.24, 11.26, 12.37, 9.73, 6.10,
5.84, 12.00, 8.70, 10.15, 10.62, 5.21, 11.34, 9.39,
9.96, 4.80, 10.97, 11.51, 12.44, 11.17, 12.43, 9.41,
10.78, 11.05, 10.85, 10.68, 9.02, 12.37, 10.43,
11.96, 10.93, 10.59, 10.76, 8.27, 9.09, 9.32, 9.36,
10.51, 11.70, 11.76, 10.72, 7.23, 9.34, 9.39, 11.53,
9.85, 10.68, 11.19, 11.29, 10.14, 12.88, 8.85, 10.88,
11.17, 13.30, 10.45, 10.13, 12.07, 10.57, 10.20, 9.74,
8.09, 10.62, 11.12, 13.98, 11.87, 13.48, 11.00, 5.86,
11.24, 10.14, 10.58, 11.04, 9.03, 9.67, 10.73, 10.21,
9.99, 10.98, 5.49, 10.28, 10.70, 13.00, 11.98, 10.04,
10.79, 9.65, 10.05, 13.12, 9.41, 4.32, 10.77, 11.40)
boxplot(m3)
# создадим новый вектор без выбросов m2_n
ind <- which(m3 %in% boxplot.stats(m3)$out)
m3_n <- m3[-ind]
boxplot(m3_n)
# тест на нормальное распределение
shapiro.test(m3) # m3 c выбросами
shapiro.test(m3_n) # m3_n без выбросами
# p-value = 1.677e-07 (m3) значительно больше 0.05
# p-value = 0.7374 (m3_n) значительно больше 0.05
# нулевая гипотеза в силе: данные подчинены
# закону нормального распределения
# видим что есть небольшой завал слева и немного высоковато
# т.е. As и Ex не равны нулю
# Для нормального распределения коэффициент асимметрии равен нулю,
# а эксцесс — трём. Если эксцесс сильно отличается от трёх,
# то говорят о наличии «тяжёлых хвостов»
#install.packages("moments")
library("moments")
skewness(m3) # коэффициент асимметрии (скошенность)
kurtosis(m3) # эксцесс (пикообразность, крутизна)
skewness(m3_n) # коэффициент асимметрии (скошенность)
kurtosis(m3_n) # эксцесс (пикообразность, крутизна)
qqnorm(m3)
qqline(m3, col='red', lwd=2)
qqnorm(m3_n)
qqline(m3_n, col='red', lwd=2)
setwd('C:/R myFunction')
source('Tndf.R')
Tndf(data = round(m3_n), Ymax = 0.65)
sum(DF$Freq)
sum(DF$Tfreg)
sum(DF$ERROR)