Моделирование рассеивания заданной функции с последующим ее регрессионным анализом (с применением predict)
Пусть у нас некоторая функция задана с помощью формулы. Мы получаем ряда значений зависимости y(x) для заданной функции. Собственно, наша задача внести в значения x и y некоторые погрешности (то есть создать вокруг некой точки x1,y1 заданное число n дополнительных точек, координаты которых будут изменены путем добавления некой погрешности, которая в свою очередь подчинена закону нормального распределения). Проще всего создать специальную функцию fr «функцию рассеивания»:
# функция рассеивания
fr = function(data, N, SD){
XR = c()
for(k in 1:length(data)){
x = data + rnorm(length(data), 0, SD)
XR = c(XR, x)
}
XR <<- XR
}
В качестве первого примера возьмем простейшую линейную функцию y = x*2 – 5 и вычислим все выходные значения y при всех значениях x на интервале от -3 до 3 с шагом 1. В результате на языке R мы получим следующую конструкцию:
x = seq(-3,3, 1)
y = x*2 - 5
sd = 0.1
n = 5
А теперь применим два раза (для x и y) функцию рассеивания (разброс sd = 0.1 и количество точек рассеивания n = 5) и мы получим следующую конструкцию:
xr = fr(data = x, N = n, SD = sd)
yr = fr(data = y, N = n, SD = sd)
plot(xr, yr)
#lines(x, y, lwd = 2)
grid(col='black')
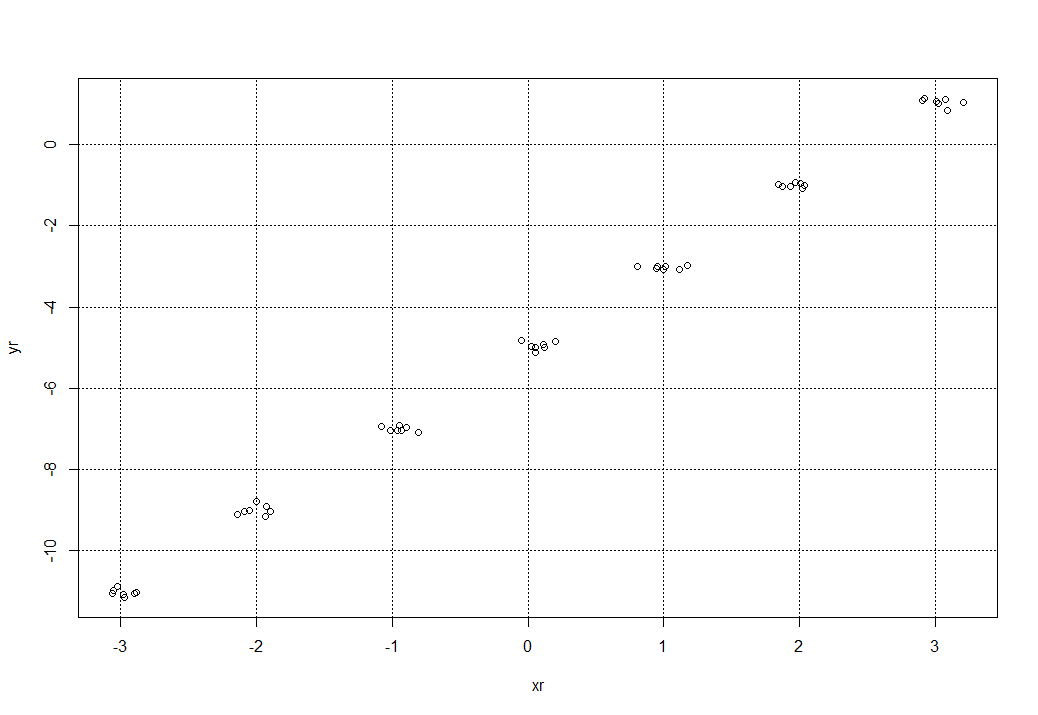
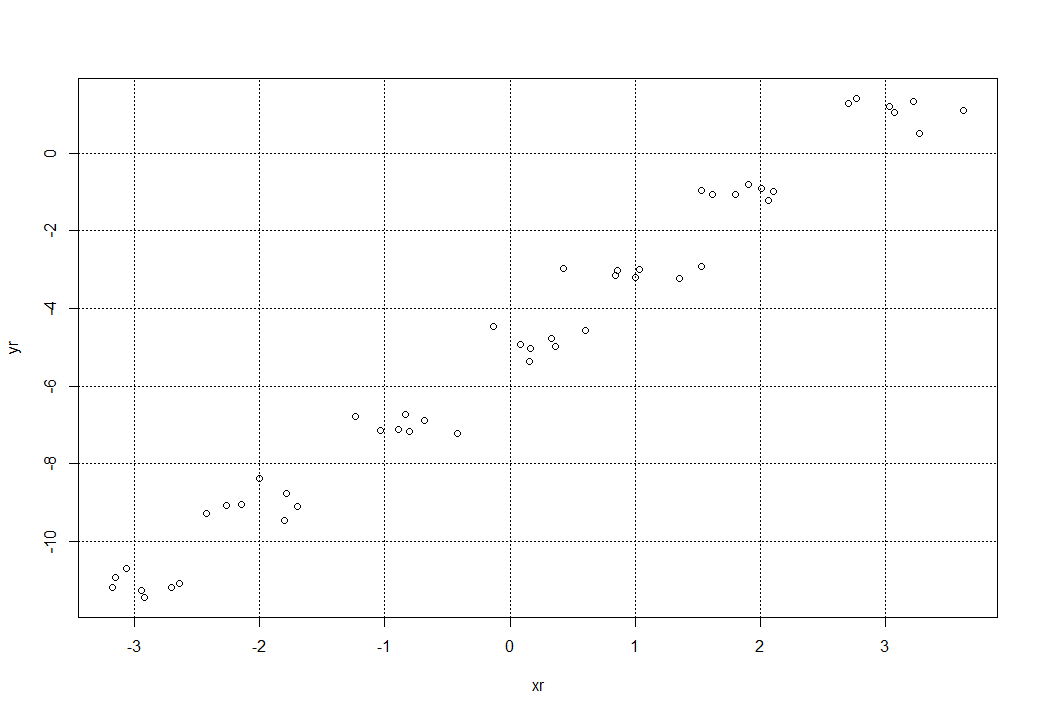
Обратим внимание на полученный график рассеивания, мы получили вокруг исходных точек, заданных исходной функции x и y по 5 дополнительных разбросанных случайных точек. Величину разброса можно увеличить, увеличив значение, например при sd = 0.3 получим уже такую картину:
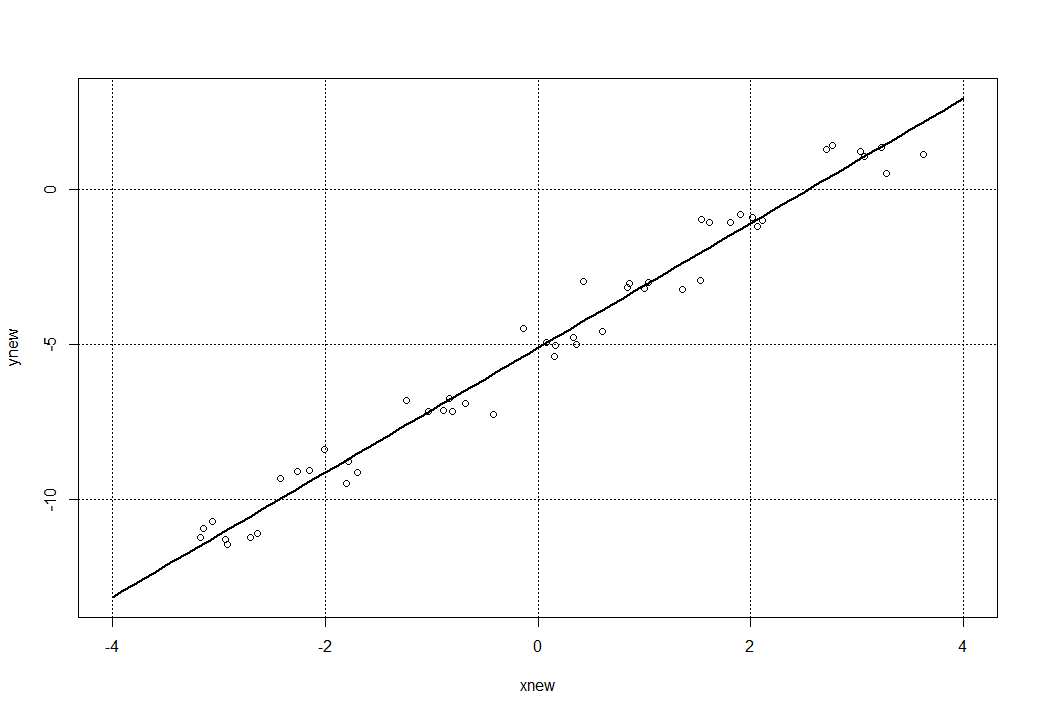
Теперь применим функцию predict и проведем регрессионный анализ. Нас будет интересовать поиск коэффициентов искомой функции, с тем чтобы в итоге найти такую функцию, график которой прошел бы через исходные точки заданной функции x и y, несмотря на помеху (или «шум») созданных вокруг последней. Мы получим следующую конструкцию:
models = lm(yr ~ poly(xr, degree = 1, raw = T))
summary(models)
R = round(summary(models)$r.squared*100,4)
> summary(models) Call: lm(formula = yr ~ poly(xr, degree = 2, raw = T)) Residuals: Min 1Q Median 3Q Max -3.6753 -0.7443 -0.2251 0.2294 4.1270 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -4.50363 0.28912 -15.577 <2e-16 *** poly(xr, degree = 2, raw = T)1 0.03241 0.09690 0.334 0.74 poly(xr, degree = 2, raw = T)2 0.89074 0.05409 16.468 <2e-16 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 1.351 on 46 degrees of freedom Multiple R-squared: 0.8551, Adjusted R-squared: 0.8488 F-statistic: 135.8 on 2 and 46 DF, p-value: < 2.2e-16 |
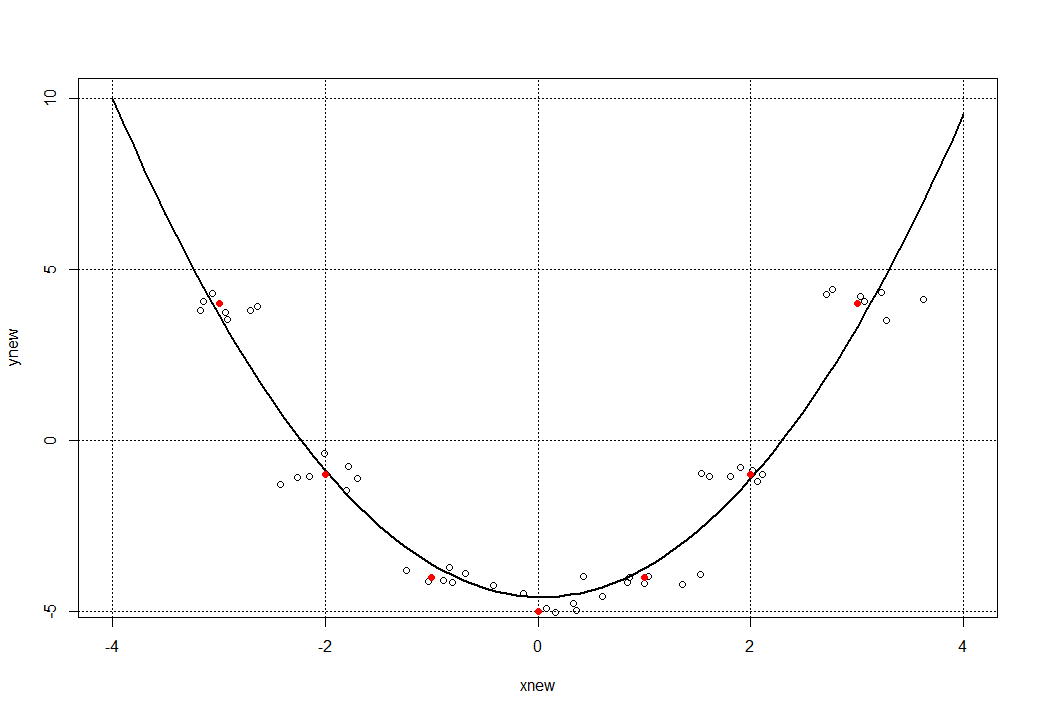
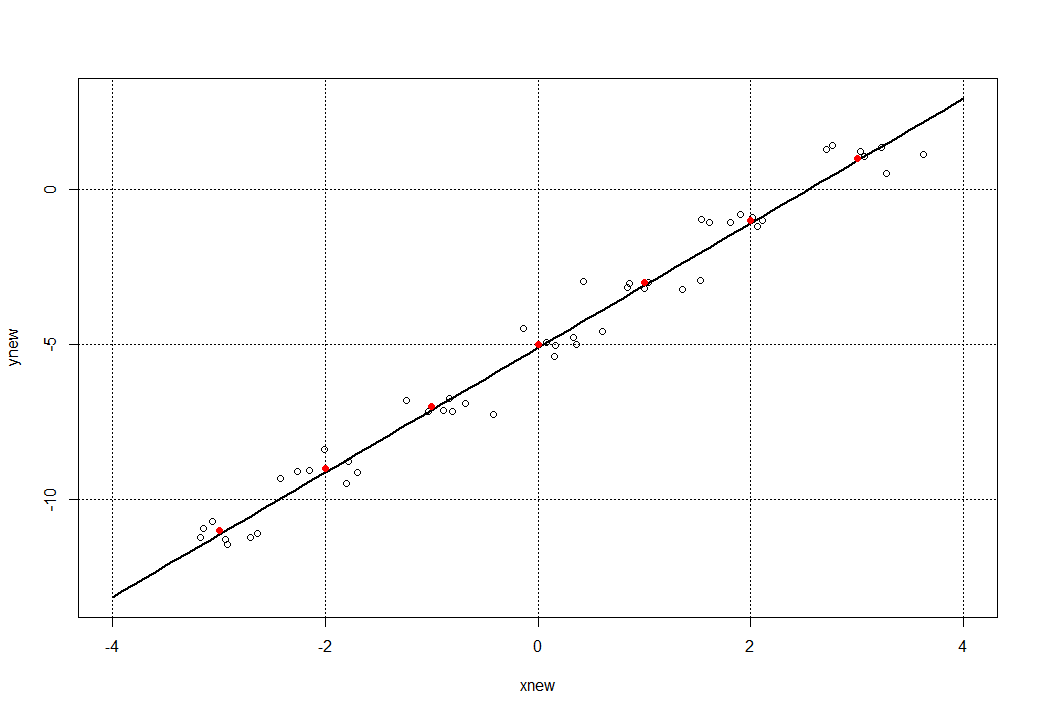
Обратим внимание на параметр degree = 1, который должен указывает на полином второй степени и выше (но мы оставим все без изменений, так как в квадратичной функции вида f(x) = a x^2 + b x + c при а = 0 мы получим линейную функцию (как в нашем примере). А нам осталось по найденной модели models с помощью функции predict получить новые данные (расширим диапазон значений х: xnew = seq(-4, 4, 0.1) и построить график и наложить на него все точки, включая и точки рассеивания функции. Получаем такую конструкцию:
#summary(models)$adj.r.squared
xnew = seq(-4, 4, 0.1)
ND = data.frame(xr = xnew)
ynew = predict(models, newdata = ND)
plot(xnew, ynew, lwd = 2, 'l')
points(xr, yr)
grid(col='black')
#lines(x, y, col = 'red')
cat('Коэффициент корреляции =', R, '%')
> cat('Коэффициент корреляции =', R, '%')
Коэффициент корреляции = 97.7038 %
Вывод: несмотря на «помеху» в виде пяти дополнительных точек, разбросанных вокруг исходных x и y мы получили довольно прекрасный результат (коэффициент корреляции = 97.7038 %). А теперь для еще большей наглядности раскрасим исходные точки исходных x и y красным цветом:
points(x, y, col = 'red', pch = 16)
А теперь выполним все тоже самое но для квадратичной функции (полный скрипт привожу ниже):
x = seq(-3,3, 1)
y = x^2 - 5
sd = 0.3
n = 5
set.seed(454)
xr = fr(data = x, N = n, SD = sd)
yr = fr(data = y, N = n, SD = sd)
plot(xr, yr)
#lines(x, y, lwd = 2)
grid(col='black')
models = lm(yr ~ poly(xr, degree = 2, raw = T))
summary(models)
R = round(summary(models)$r.squared*100,4)
#summary(models)$adj.r.squared
xnew = seq(-4, 4, 0.1)
ND = data.frame(xr = xnew)
ynew = predict(models, newdata = ND)
plot(xnew, ynew, lwd = 2, 'l')
points(xr, yr)
grid(col='black')
#lines(x, y, col = 'red')
cat('Коэффициент корреляции =', R, '%')
points(x, y, col = 'red', pch = 16)