Регрессионный анализ поиск функции по данным из файла
Регрессионный анализ — набор статистических методов, которые оценивают связь между несколькими переменными с помощью построения математических моделей. Они определяют, как изменения одного параметра влияют на другой. В основе регрессионного анализа лежит построение математической модели, которая описывает, как изменения независимых переменных приводят к изменениям зависимой переменной. В нашей практической задачи будет поиск математической модели функции на основании данных зависимости взятых непосредственно из файла (сразу предлагаю загрузить этот файл datafunc.txt с нашего сайта и скопировать его в рабочую директорию.
setwd('C:/DATA R')
data <- read.table(file = "datafunc.txt", header = TRUE)
head(data)
> head(data) x y 1 -2.00 4.0000000 2 -1.95 3.0515063 3 -1.90 2.2021000 4 -1.85 1.4460062 5 -1.80 0.7776000 6 -1.75 0.1914062 |
Проведем разведку этих данных, для чего построим точечный график:
plot(data)
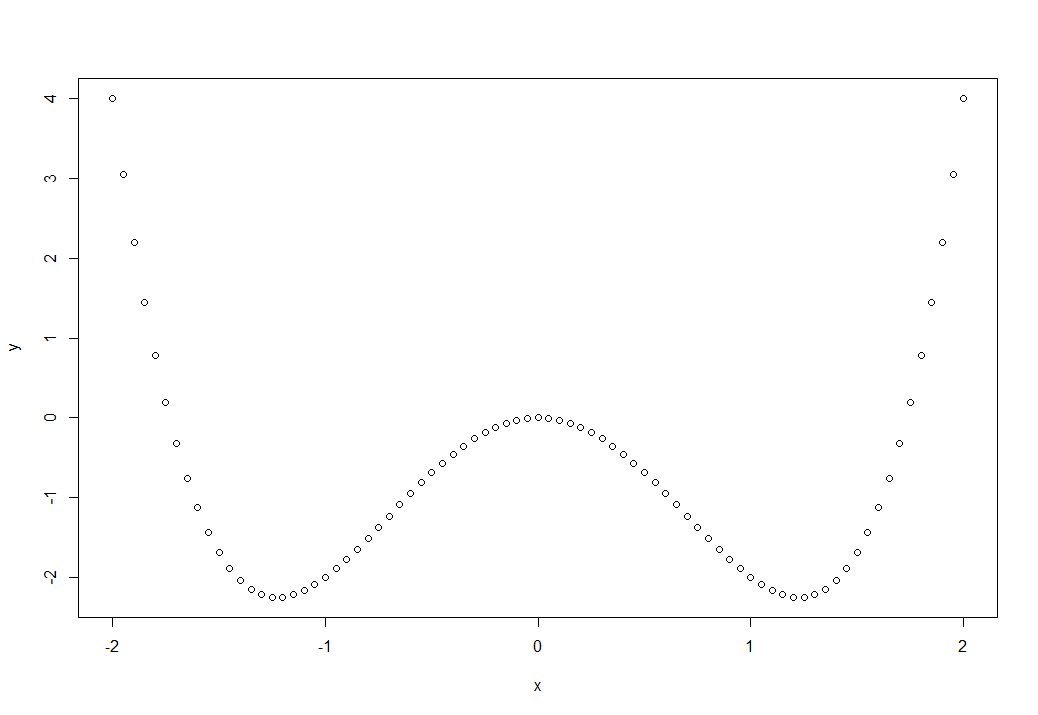
Можно сразу предположить, что у нас данные не подходят для линейной и квадратической функции, предположим что это функция описывается полиномом третьей степени. Давайте выясним это:
md = lm(data$y ~ poly(data$x, degree = 3, raw = TRUE))
summary(md)
> md = lm(data$y ~ poly(data$x, degree = 3, raw = TRUE)) > summary(md) Call: lm(formula = data$y ~ poly(data$x, degree = 3, raw = TRUE)) Residuals: Min 1Q Median 3Q Max -1.6409 -1.2179 -0.0419 1.1311 3.3891 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -1.439e+00 2.185e-01 -6.585 5.01e-09 *** poly(data$x, degree = 3, raw = TRUE)1 -3.011e-16 3.117e-01 0.000 1 poly(data$x, degree = 3, raw = TRUE)2 5.125e-01 1.192e-01 4.300 4.96e-05 *** poly(data$x, degree = 3, raw = TRUE)3 2.262e-16 1.162e-01 0.000 1 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 1.311 on 77 degrees of freedom Multiple R-squared: 0.1936, Adjusted R-squared: 0.1622 F-statistic: 6.163 on 3 and 77 DF, p-value: 0.0008243 |
R-squared: 0.1936 очень слабая зависимость, нас это абсолютно не устраивает, поэтому увеличим степень полинома на единицу и проанализируем модель полинома четвертой степени
md1 = lm(data$y ~ poly(data$x, degree = 4, raw = TRUE))
summary(md1)
> md1 = lm(data$y ~ poly(data$x, degree = 4, raw = TRUE)) > summary(md1) Call: lm(formula = data$y ~ poly(data$x, degree = 4, raw = TRUE)) Residuals: Min 1Q Median 3Q Max -1.993e-14 -7.351e-16 -1.341e-16 4.335e-16 9.448e-15 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) -3.948e-15 6.244e-16 -6.322e+00 1.61e-08 poly(data$x, degree = 4, raw = TRUE)1 -2.058e-15 7.123e-16 -2.888e+00 0.005041 poly(data$x, degree = 4, raw = TRUE)2 -3.000e+00 9.545e-16 -3.143e+15 < 2e-16 poly(data$x, degree = 4, raw = TRUE)3 9.738e-16 2.655e-16 3.668e+00 0.000451 poly(data$x, degree = 4, raw = TRUE)4 1.000e+00 2.604e-16 3.840e+15 < 2e-16 (Intercept) *** poly(data$x, degree = 4, raw = TRUE)1 ** poly(data$x, degree = 4, raw = TRUE)2 *** poly(data$x, degree = 4, raw = TRUE)3 *** poly(data$x, degree = 4, raw = TRUE)4 *** --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 2.996e-15 on 76 degrees of freedom Multiple R-squared: 1, Adjusted R-squared: 1 F-statistic: 4.57e+30 on 4 and 76 DF, p-value: < 2.2e-16 |
Multiple R-squared: 1 теперь все идеально! Мы поймали функцию! Приступаем теперь к построению графика для такой задачи нам поможет функция predict
x = data$x
y = data$y
md1 = lm(y ~ poly(x, degree = 4, raw = TRUE))
summary(md1)
xn = seq(-2.2, 2.2, 0.05)
xx = data.frame(x = xn)
yn = predict(md1, xx)
plot(xn, yn, 'l', lwd = 2)
points(data, lwd = 2)
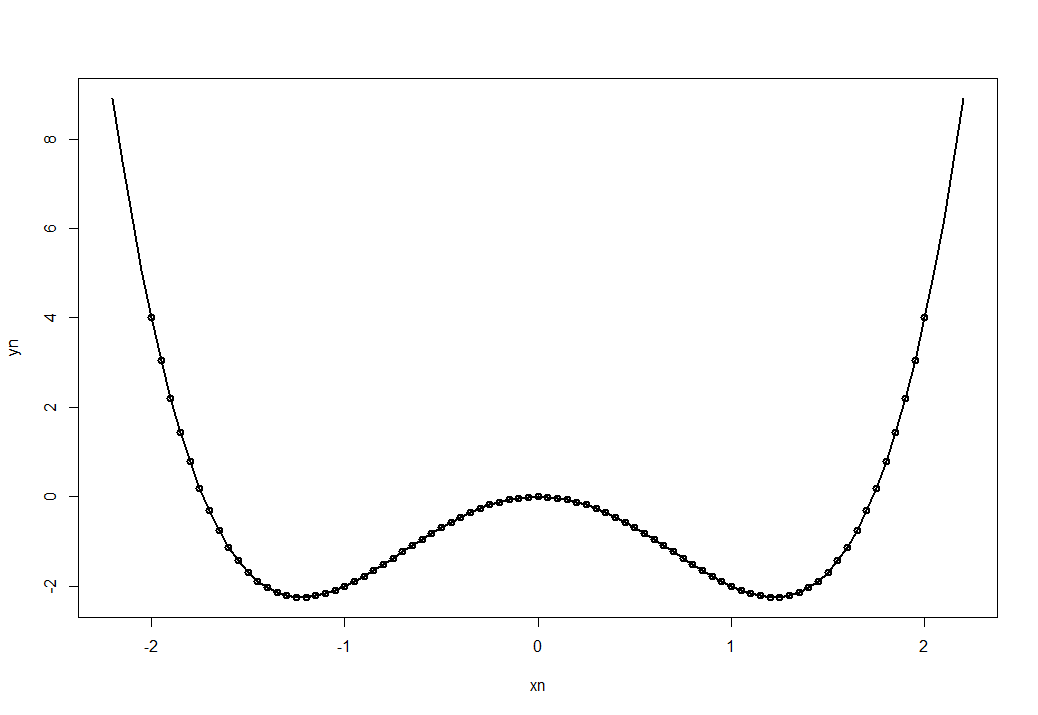
График абсолютно точно проходит через все точки данных - задача решена! И попробуем сохранить новые данные в файл
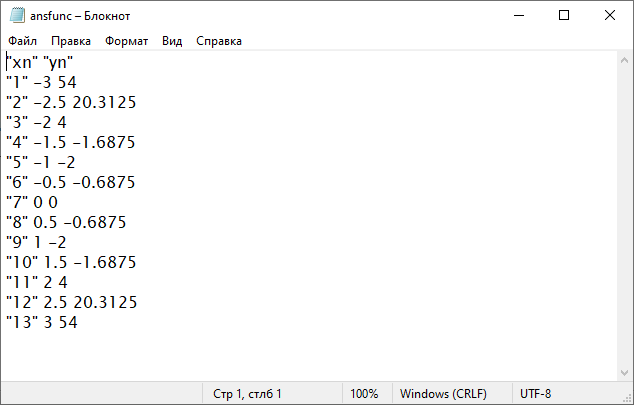
# построить таблицу значений функции на интервале -3, 3 с шагом 0.5
# и записать данные в файл
options(scipen = 100, digits = 4)
xn = seq(-3, 3, 0.5)
xx = data.frame(x = xn)
yn = round(predict(md1, xx), 4)
dt = data.frame(xn, yn)
dt
write.table(dt, file = "ansfunc.txt")