Создаем Генеральную Совокупность из выборки малого объема
Возможно из выборки небольшого объема попытаться создать модель генеральной совокупности? С нашей вычислительной техникой это вполне реальная задача, в ходе которой из небольшой вуборки путум бутстрепа мы создадим искусственную генеральную выборку необходимого объема. Для начала загрузите с нашего сайта скрипт функции MinInGS и на диске С создайте папку R myFunction куда и сохраните скачанный файл. В скрипте укажем путь к этому файлу
setwd('C:/R myFunction')
source('MinInGS.R')
А теперь создадим реальную генеральную совокупность GSa в которой будут 2000 чисел сгенерированные по закону нормального распределения с средним показателем 100 и стандартным отклонением в 3. Дальше случайно извлечем из генеральной совокупности 25 чисел, которые и образуют выборку малого объема х без повторов:
set.seed(454)
GSa = rnorm(2000, 100, 3)
x = sample(GSa, size = 25, replace = F)
summary(GSa)
> summary(GSa) Min. 1st Qu. Median Mean 3rd Qu. Max. 88.57 97.91 99.97 99.91 101.95 109.56 |
Приступим к основной задаче: попытаемся из вектора х получить искусственно генеральную совокупность того же размера что и исходная. А затем сравним описательные статистики обеих ГС
MinInGS(data = x, N = 2000, cl = 0.99)
Создана Генеральная Совокупность в количестве элементов = 2000 summary data Min. 1st Qu. Median Mean 3rd Qu. Max. 93.97 98.02 100.12 99.88 102.24 105.49 summary GS Min. 1st Qu. Median Mean 3rd Qu. Max. 88.58 97.60 99.92 99.85 102.11 110.24 Доверительный интервал 99 % для данных: [1] 98.0158 101.7373 для Генеральной Совокупности: [1] 99.66401 100.04070 |
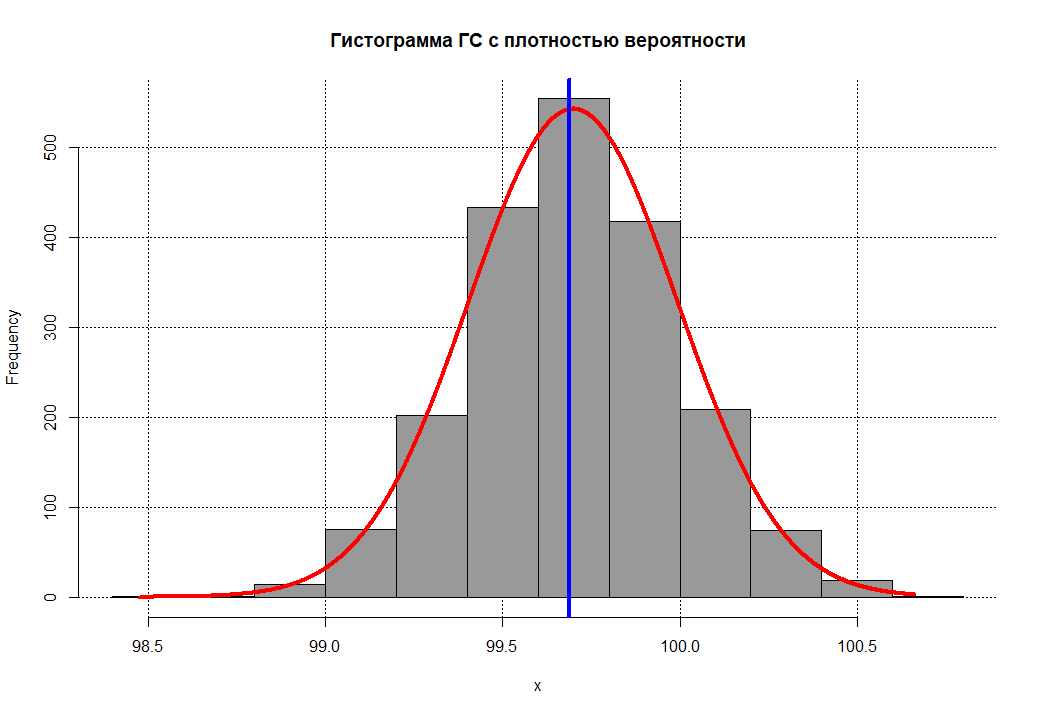
Обратите внимание что искусственно полученная генеральная совокупность находится в векторе GS. Пройдемся по описательной статистике
summary(GSa)
summary(GS)
> summary(GSa) Min. 1st Qu. Median Mean 3rd Qu. Max. 88.57 97.91 99.97 99.91 101.95 109.56 > summary(GS) Min. 1st Qu. Median Mean 3rd Qu. Max. 88.58 97.60 99.92 99.85 102.11 110.24 |
Здесь большинство показателей вполне неплохо согласуются, исключение составляет только стандартные отклонения (оно и понятно ведь мы воссоздали модель ГС из вектора в 25 значений, которые взяты из исходного вектора истинной генеральной совокупности и могли при этом не сильно отличаться друг от друга, а отсюда и разница в стандартных отклонениях:
> sd(GSa) [1] 2.983601 > sd(GS) [1] 3.266855 |
Поэтому проведем статистический трест между реальной Генеральной Совокупностью (из нее мы извлекли 25 значений в малую выборку) и искусственно созданной ГС методом бутстрепа (из 25 исходных данных превратили в 2000).
t.test(GSa, GS)
> t.test(GSa, GS) Welch Two Sample t-test data: GSa and GS t = 0.58775, df = 3965.6, p-value = 0.5567 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -0.1358122 0.2521039 sample estimates: mean of x mean of y 99.91050 99.85235 |
p-value = 0.5567 значит нулевая гипотеза (она утверждает что нет статистически значимых отличий между сравниваемыми ГС) остается в силе. А следовательно мы доказали что возможно (конечно с определенной долей вероятности, она тем выше чем выше объем выборки из ГС) восстановить модель искусственной ГС из малой выборки при помощи бутстрепа.