Анализ выборки или полная описательная статистика
Описательная статистика – занимается характеристикой (описанием) картины случайного рассеяния по совокупности данных. В соответствии с законом распределения данных решаются вопросы выбора и вычислений надлежащих показателей.
Описательная статистика — это краткие информационные коэффициенты, которые обобщают заданный набор данных, представляющий либо всю совокупность, либо выборку из совокупности. Описательная статистика делится на показатели центральной тенденции и показатели изменчивости (разброса). Показатели центральной тенденции включают среднее значение, медиану и моду, а показатели изменчивости включают стандартное отклонение, дисперсию, минимальные и максимальные значения, эксцесс и асимметрию.
Скрипт ниже помогает провести все необходимые расчеты, связанные с описательной статистикой и для большей простоты и наглядности выполним все задачи поэтапно.
- Проверка данных на NA в R — это логический элемент, который обозначает отсутствующее значение. В случае обнаружения можно или удалить или заменить их на средние значения.
- Анализ данных на выбросы. В случае и обнаружения будет создан вектор в которых не будет сильно отклонившихся величин.
- Расчет описательной статистики
- Расчет доверительного интервала
- Проверка на нормальное распределение
Все описанное выше легко реализовать в среде программирования R. При этом постараемся максимально автоматизировать процесс обработки данных. В итоге у меня получился скрипт (завернутый в функцию) statall который можно загрузить с нашего сайта жми сюда. А теперь посмотрим как работает данный скрипт. Обратите внимание что в процессе работы скрипт будет обращаться к библиотекам (которые нужно будет установить заранее, если они не установлены на вашем компьютере)
library(DescTools)
library(nortest)
setwd('C:/R myFunction')
source('statall.R')
options(scipen = 999, digits = 4)
set.seed(55)
x = round(rnorm(500, 100, 5),1)
x = c(x, NA, NA, NA)
statall(Data = x,CI = 97)
Первым делом скрипт проверит данные на выбросы и пропущенные значения. Сначала будет построен боксплот (и если увидем кружочки - то выбросы имеют место быть). Далее нажимаем кнопку ввода и будет построен боксплот но уже без выбросов.
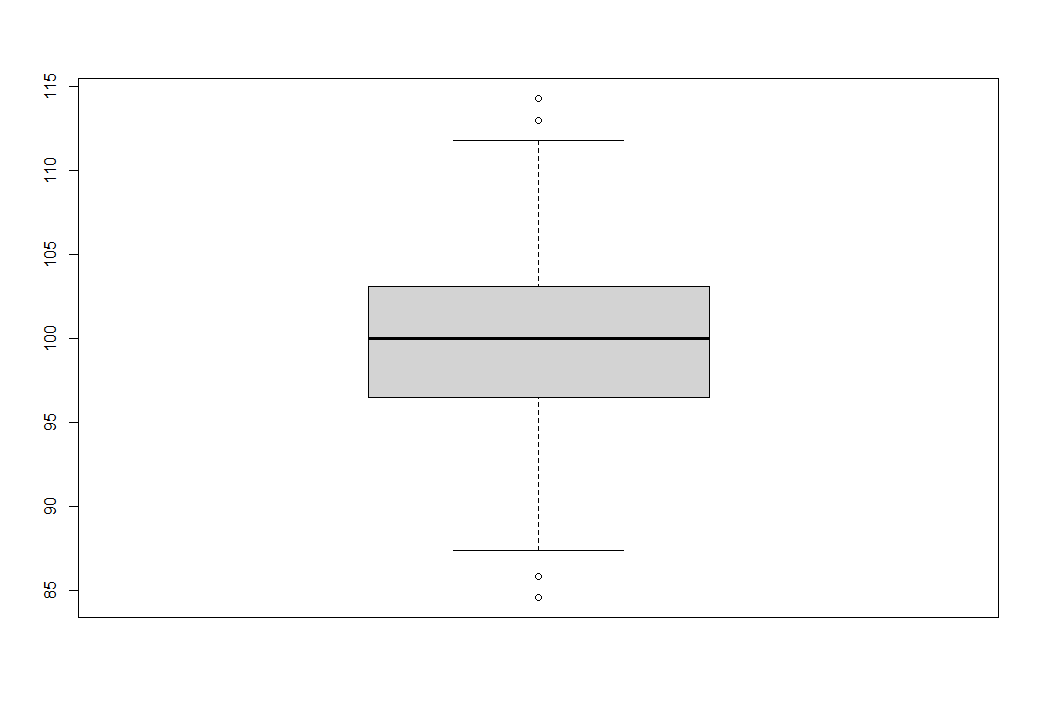
> setwd('C:/R myFunction')
> source('statall.R')
> options(scipen = 999, digits = 4)
> set.seed(55)
> x = round(rnorm(500, 100, 5),1)
> x = c(x, NA, NA, NA)
> statall(Data = x,CI = 97)
Нажмите [enter] для продолжения
всего удалено выбросов: 4
всего удалено NA: 3
|
Снова нажимаем клавишу ввода и далее автоматически пройдут четыре теста на нормальность исходных данных (два графических QQ тест и гистограмма) и отчеты еще по двум можно узнать в окне вывода), а так же описательные статистики исходных данных.
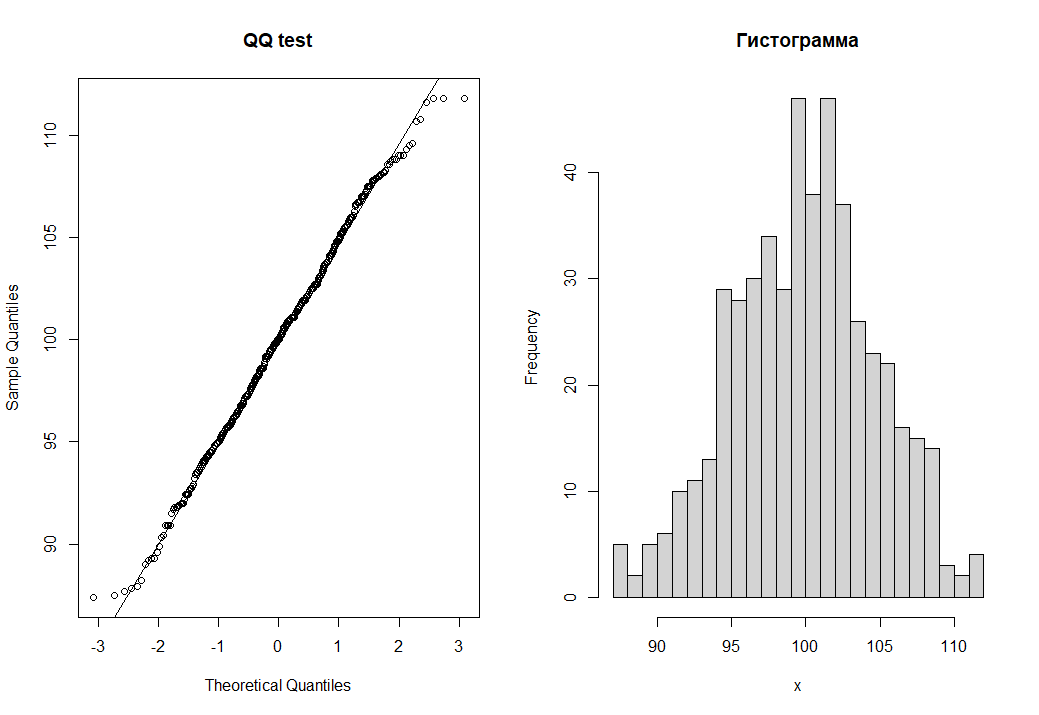
Нажмите [enter] для продолжения N mean median SD As Ex min max 496.00000 99.93952 100.00000 4.81081 -0.06067 -0.28476 87.40000 111.80000 Vx 4.81372 ------------------------------------------------------------ Расчет доверительного интервала для среднего значения с доверительным интервалом: 97 % mean lwr.ci upr.ci 99.94 99.47 100.41 ------------------------------------------------------------ Проверка на нормальное распределение тест Шапиро-Уилка указывает на нормальное распределение данных ------------------------------------------------------------ тест Андерсона-Дарлинга указывает на нормальное распределение данных ------------------------------------------------------------ |
Снова нажимаем клавишу ввода и нашему вниманию предстанет гистограмма (данных без выбросов) и кривые плотности распределения: красным цветом Генеральная совокупность, черным наши данные без выбросов, и наконец синяя прерывистая линия данные с выбросами (для сравнения). На этом работа скрипта завершается.
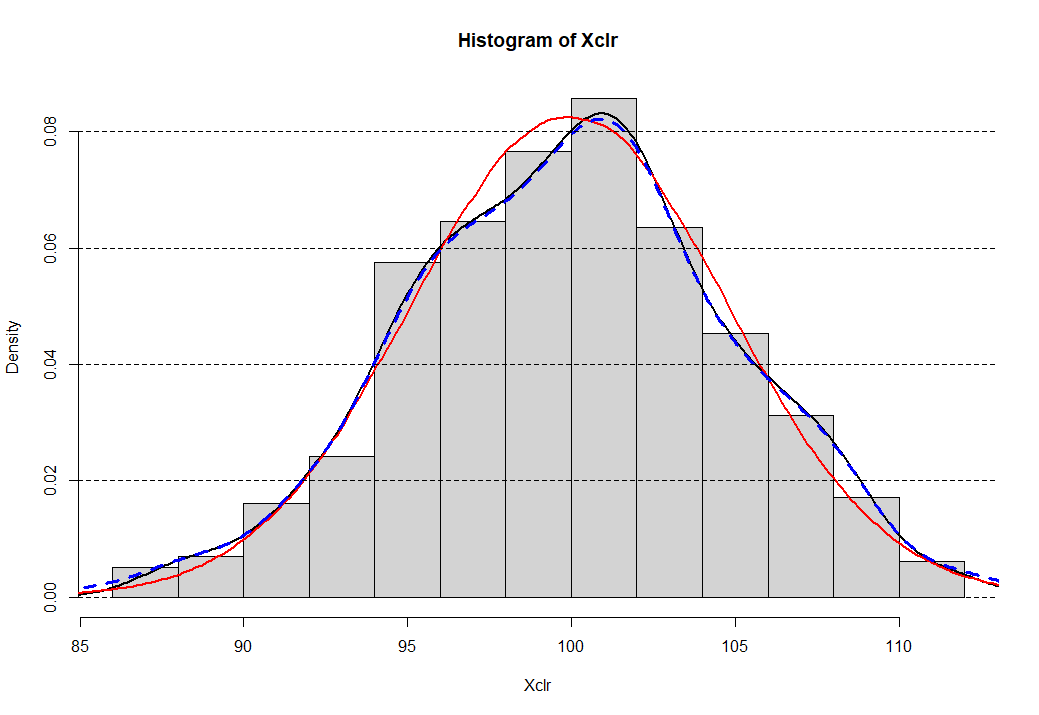
Подробнее про некоторые статистики.
Усечённое среднее, среднее по цензурированной выборке
-
Считается так: выборка упорядочивается по возрастанию, из неё убирается 5% наблюдений слева и справа (наименьшие и наибольшие), потом по такой усечённой или цензурированной выборке считается обычное среднее арифметическое.
-
Наравне с медианой считается более устойчивой оценкой среднего, так как после усечения выборки такой показатель уже несильно зависит от слишком больших или слишном маленьких (нетипичных) значений в выборке. То есть, при наличии нетипичных наблюдений в выборке (выбросов) такое среднее более адекватно отражает реальность, чем обычное среднее арифметическое.
Коэффициент асимметрии
-
Показатель принимает значения примерно от -3 до 3. Значение 0 соответствует симметричному распределению (например, нормальному, вспомните график плотности, симметричный относительно математического ожидания). Значения меньше 0 соответствуют распределению, которое скошено влево (длинный хвост «слева»), значения больше 0 соответствуют распределению, которое скошено вправо (длинный «хвост» справа).
-
В нашем случае распределение почти симметричное, коэффициент близок к нулю, но при это оно немного скошено вправо, поэтому значение больше 0.
Коэффициент эксцесса
-
Показатель принимает значения примерно от -3 до 3 и отвечает за выраженность пика распределения. Чем больше значение коэффициента, тем более выраженный пик. Стандартное нормальное распределение имеет коэффициент эксцесса равный 0. Отрицательные значения коэффициента соответствуют более «плоским» и «гладким» распределениям, у которых пик не такой заметный.
source('Statall.R')
options(scipen = 999, digits = 3)
set.seed(5454)
# пример 1
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
x = rnorm(250, 50, 5)
x = c(x, rep(NA, 10))
statall(Data = Xclr, CI = 95)
x = Xclr
#пример 2
# масса грецких орехов урожай 2023 года
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
mass = c(11.95, 10.95, 12.56, 9.16, 10.08, 10.72, 9.29, 6.15,
5.12, 11.16, 9.51, 10.73, 10.44, 10.10, 10.10, 11.35,
13.05, 12.09, 11.09, 7.86, 5.12, 6.41, 8.76,
10.40, 11.36, 6.07, 11.11, 9.29, 10.25, 11.72,
9.82, 8.07, 9.20, 9.65, 9.87, 12.39, 10.72, 11.84,
9.81, 10.10, 11.04, 10.08, 12.91, 10.30, 12.80,
9.40, 8.65, 10.21, 9.50, 10.97, 11.65, 8.27, 9.90,
9.18, 9.83, 10.41, 10.24, 11.26, 12.37, 9.73, 6.10,
5.84, 12.00, 8.70, 10.15, 10.62, 5.21, 11.34, 9.39,
9.96, 4.80, 10.97, 11.51, 12.44, 11.17, 12.43, 9.41,
10.78, 11.05, 10.85, 10.68, 9.02, 12.37, 10.43,
11.96, 10.93, 10.59, 10.76, 8.27, 9.09, 9.32, 9.36,
10.51, 11.70, 11.76, 10.72, 7.23, 9.34, 9.39, 11.53,
9.85, 10.68, 11.19, 11.29, 10.14, 12.88, 8.85, 10.88,
11.17, 13.30, 10.45, 10.13, 12.07, 10.57, 10.20, 9.74,
8.09, 10.62, 11.12, 13.98, 11.87, 13.48, 11.00, 5.86,
11.24, 10.14, 10.58, 11.04, 9.03, 9.67, 10.73, 10.21,
9.99, 10.98, 5.49, 10.28, 10.70, 13.00, 11.98, 10.04,
10.79, 9.65, 10.05, 13.12, 9.41, 4.32, 10.77, 11.40)