Проверка на нормальность
Тестирование данных на нормальность часто является первым этапом их анализа, так как большое количество статистических методов исходит из предположения нормальности распределения изучаемых данных.
Например, пусть необходимо проверить гипотезу о равенстве средних значений в двух независимых выборках. Для этой цели подходит критерий Стьюдента. Но применение критерия Стьюдента обосновано, только если данные подчиняются нормальному распределению. Поэтому перед применением критерия необходимо проверить гипотезу о нормальности исходных данных. Или проверка остатков линейной регрессии на нормальность — позволяет проверить, соответствует ли применяемая модель регрессии исходным данным.
Нормальное распределение естественным образом возникает практически везде, где речь идёт об измерении с ошибками. Более того, в силу центральной предельной теоремы, распределение многих выборочных величин (например, выборочного среднего) при достаточно больших объёмах выборки хорошо аппроксимируется нормальным распределением вне зависимости от того, какое распределение было у выборки исходно. В связи с этим становится понятным, почему проверке распределения на нормальность стоит уделить особое внимание. В дальнейшем речь пойдёт о так называемых критериях согласия (goodness-of-fit tests). Проверяться будет не просто факт согласия с нормальным распределением с определёнными фиксированными значениями параметров, а несколько более общий факт принадлежности распределения к семейству нормальных распределений со всевозможными значениями параметров.
Проверку выборки на нормальность можно производить несколькими путями. Первая группа методов - графические. Для начала можно вспомнить, какой вид у графика нормального распределения (гистограмма, график плотности и т.п.), как в нормальном распределении соотносятся среднее, мода, медиана, какими должны быть асимметрия и эксцесс, выполняется ли «правило 3-х сигм». Про всё это я написал в статье про нормальное распределение. Вот с помощью такой описательной статистики можно оценить выборку на нормальность (обычно приемлемо отклонение на порядок ошибки рассчитываемого параметра). Вторая группа методов — критерии нормальности.
Критерии нормальности
Список критериев нормальности:
- Критерий Шапиро-Уилка
- Критерий асимметрии и эксцесса
- Критерий Дарбина
- Критерий Д’Агостино
- Критерий Васичека
- Критерий Дэвида-Хартли-Пирсона
- Критерий хи-квадрат
- Критерий Андерсона-Дарлинга
- Критерий Филлибена
- Критерий Колмогорова-Смирнова
- Критерий Мартинса-Иглевича
- Критерий Лина-Мудхолкара
- Критерий Шпигельхальтера
- Критерий Саркади
- Критерий Смирнова-Крамера-фон Мизеса
- Критерий Локка-Спурье
- Критерий Оя
- Критерий Хегази-Грина
- Критерий Муроты-Такеучи
Графические способы проверки на нормальное распределение
Самый простой графический способ проверки характера распределения данных — построение гистограммы (с помощью функции hist() — это сделать несложно). Если гистограмма имеет колоколообразный симметричный вид, можно сделать заключение о том, что анализируемая переменная имеет примерно нормальное распределение. Однако при интерпретации гистограмм следует соблюдать осторожность, поскольку их внешний вид может сильно зависеть как от числа наблюдений, так и от шага, выбранного для разбиения данных на классы. Скопируйте и выполните скрипт ниже (обратите внимание на кривую нормального распределения красного цвета и гистограмму). Какой можно сделать вывод?
set.seed(55)
x= c(rnorm(100, 0, 1))
plotNormalHistogram( x, prob = FALSE, col="grey60", border="black",
main = "Normal Distribution overlay on Histogram",
length = 10000, linecol="red", lwd=4 )
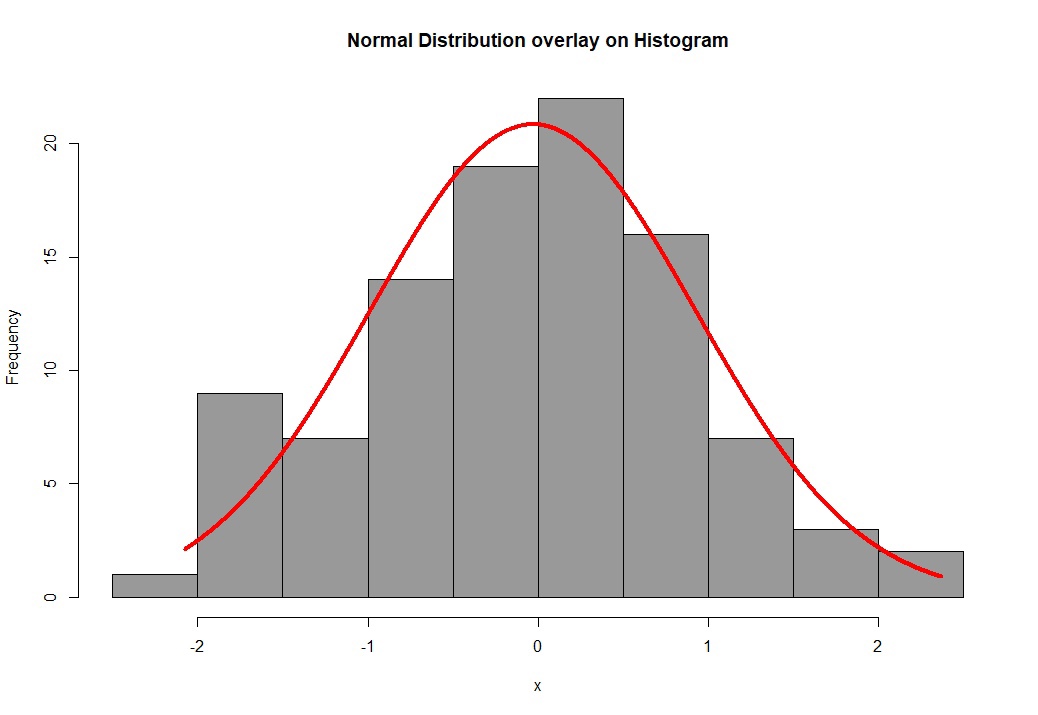
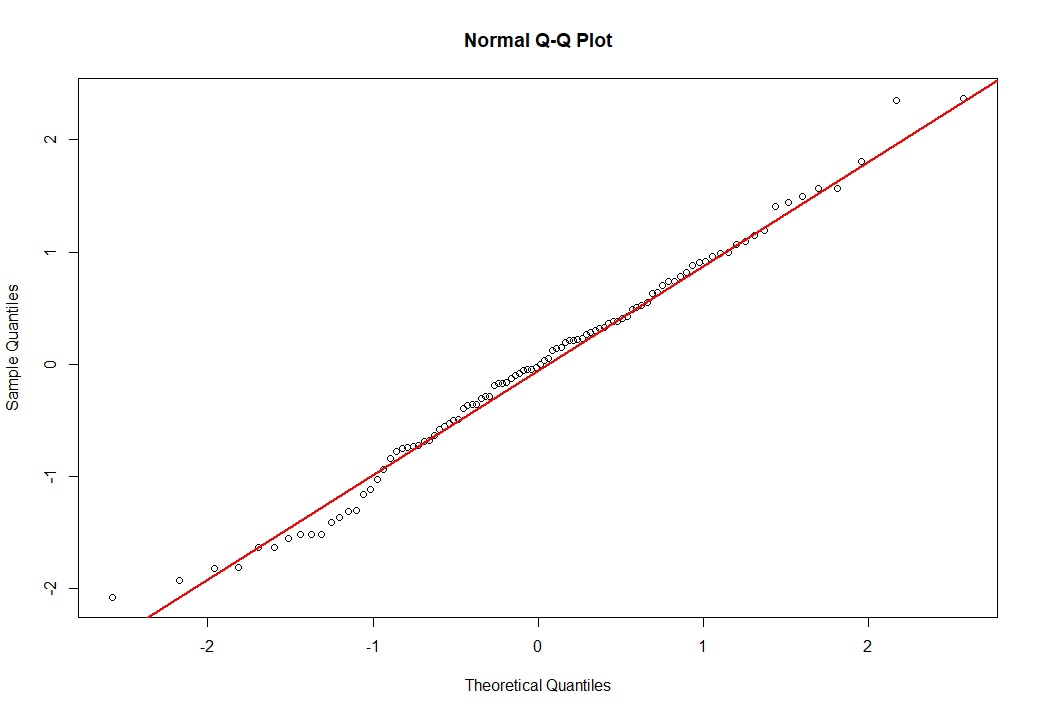
Может показаться что данные не совсем соответствуют нормального распределению (такое бывает при относительно небольшой выборке, в нашем примере вектор случайных значений состоит только из ста вариант, попробуйте самостоятельно увеличить генерацию случайных чисел до 1000 и сравните результаты). Поэтому стоит еще провести другой графический тест. Другим очень часто используемым графическим способом проверки характера распределения данных является построение т.н. графиков квантилей (Q-Q plots, Quantile-Quantile plots). На таких графиках изображаются квантили двух распределений - эмпирического (т.е. построенного по анализируемым данным) и теоретически ожидаемого стандартного нормального распределения. При нормальном распределении проверяемой переменной точки на графике квантилей должны выстраиваться в прямую линию, исходящую под улом 45 градусов из левого нижнего угла графика. Графики квантилей особенно полезны при работе с небольшими по размеру совокупностями, для которых невозможно построить гистограммы, принимающие какую-либо выраженную форму. В R для построения графиков квантилей можно использовать базовую функцию qqnorm(), которая в качестве основного аргумента принимает вектор со значениями анализируемой переменной.
qqnorm(x)
qqline(x, col='red', lwd=2)
Следующий код показывает, как создать график QQ для нормально распределенного и ненормально распределенного набора данных в R:
#make this example reproducible set. seeds (0) #create data that follows a normal distribution normal_data <- rnorm(200) #create data that follows an exponential distribution non_normal_data <- rexp(200, rate=3) #define plotting region by(mfrow=c(1,2)) #create QQ plot for both datasets qqnorm(normal_data, main=' Normal ') qqline(normal_data) qqnorm(non_normal_data, main=' Non-normal ') qqline(non_normal_data)
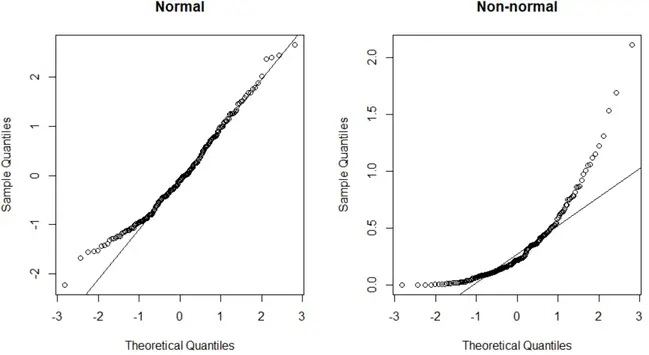
График QQ слева представляет набор данных с нормальным распределением (точки располагаются вдоль прямой диагональной линии), а график QQ справа представляет набор данных с ненормальным распределением.
Следует отметить, что интерпретация графиков квантилей при работе с небольшими выборками, происходящими из нормально распределенных генеральных совокупностей, требует определенного навыка. Дело в том, что при небольшом числе наблюдений точки на графике квантилей могут не всегда образовывать четко выраженную прямую линию. В качестве иллюстрации этого утверждения на Рисунке 3 приведены графики квантилей для 5 случайным образом сгенерированных нормально распределенных выборок по 20 наблюдений каждая (если использованный в примере пакет DAAG у Вас не установлен, выполните команду install.packages("DAAG")):
library(DAAG) qreference(m = 20, seed = 145, nrep = 5, nrows = 1)
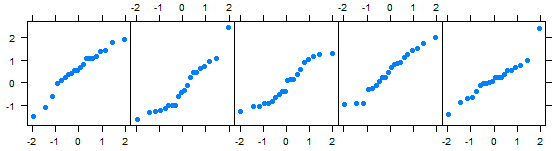
Графики квантилей для пяти случайным образом сгенерированных нормально распределенных выборок (n = 20 в каждой). Обратите внимание на то, что фигура, в которую выстраваются точки на некоторых графиках далека от прямой линии. Причина данного эффекта - в небольшом объеме наблюдений.
Формальные тесты
Существует целый ряд статистических тестов, специально разработанных для проверки нормальности распределения данных. В общем виде проверяемую при помощи этих тестов нулевую гипотезу можно сформулировать так: "Анализируемая выборка происходит из генеральной совокупности, имеющей нормальное распределение". Если получаемая при помощи того или иного теста вероятность ошибки Р оказывается меньше некоторого заранее принятого уровня значимости (например, 0.05), нулевая гипотеза отклоняется.
В R реализованы практически все имеющиеся тесты на нормальность - либо в виде стандартных функций, либо в виде функций, входящих в состав отдельных пакетов. Примером базовой функции является shapiro.test(), при помощи которой можно выполнить широко используемый тест Шапиро-Уилка:
shapiro.test(x) Shapiro-Wilk normality test data: x W = 0.98945, p-value = 0.6207 # P > 0.05 - нулевая гипотеза не отвергается
В нашем примере (полный скрипт привожу ниже) мы выдвигаем гипотезу Н0 - данные в векторе подчинены закону нормального распределения. В ходе теста мы получили p-value = 0.6207 что на порядки больше критического значения в 0.05 и следовательно наша Н0 гипотеза в высшей степени верна - выборка действительно имеет нормальное распределение. set.seed(55) x= c(rnorm(100, 0, 1)) plotNormalHistogram( x, prob = FALSE, col="grey60", border="black", main = "Normal Distribution overlay on Histogram", length = 10000, linecol="red", lwd=4 ) qqnorm(x) qqline(x, col='red', lwd=2) shapiro.test(x)