Полный анализ одномерных данных в среде R
# aod Полный анализ одномерных данных в среде R
# анализ данных ggplot
# гистограмма с отклонениями по сигмам
# данные поместить в вектор x
library(ggplot2)
library(plyr)
options(scipen = 999, digits = 4)
datatest = function(){
x = c(c(NA, 7, NA, 5, 8, 9, 10, 2, 9, 10, 11, NA, 8, 9, 17, 10, 7, 9))
}
Help=function(){
# Анализ одномерных данных в среде R предполагает работу с одной переменной.
# Это простая форма анализа, так как информация касается
# только одной изменяющейся величины.
# Некоторые шаги анализа одномерных данных в R:
# Проверка вектора данных на пропущенные значения (NA).
# Можно удалить их простым способом или с помощью функции mfNAdate(x),
# которая автоматически заменит все NA на среднее (или медиану).
# Проверка на выбросы. Для этого используется функция DvybrosBP,
# которая автоматически удаляет выбросы
# и строит ящики с усами для сравнения до и после.
# Проверка данных на нормальное распределение. Для этого применяется функция Tnorm.
# Вычисление описательной статистики.
# Она нужна, чтобы охарактеризовать анализируемые показатели.
# К описательной статистике относятся, например,
# минимальный, максимальный, средний элементы и медиана данных.
# Визуализация данных. Для этого можно использовать гистограмму
# (функция hist()) или
# график плотности (функция density() вместе с функцией plot()).
}
# 1) Проверка вектора данных x на пропущенные значения (NA)
# 2) Проверка вектора х на выбросы.
# 3) гистограмма с отклонениями по сигмам
# 4) полная описательная статистика
# 5) Тесты на нормальное распределение
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
#
# 1) Проверка вектора данных x на пропущенные значения (NA)
#
xNA = x
x = x[!is.na(x)]
# # # удалить NA в векторе х
if (length(xNA) == length(x)) {
cat('-------------------------\n')
cat('NA не обнаружены')
}else{
cat('-------------------------\n')
cat('NA обнаружены: \n')
cat('в количестве:', length(xNA) - length(x), '\n')
cat('Вектор х больше не содержит NA \n')
cat('Создан дубль исходного вектора xNA с NA \n')
cat('-------------------------\n')
}
# # # заменить NA в векторе xNA на средния значения > x1
impute.mean <- function(x) replace(x, is.na(x), mean(x, na.rm = TRUE))
x1 = impute.mean(xNA)
#
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
#
# 2) Проверка вектора х на выбросы.
#
xout = x
# создадим новый вектор без выбросов xx
ind <- which(x %in% boxplot.stats(x)$out)
xx <- x[-ind]
if (length(xout) == length(xx)) {
cat('-------------------------\n')
cat('Выбросы не обнаружены')
}else{
cat('-------------------------\n')
cat('обнаружены выбросы: \n')
cat('в количестве:', length(xout) - length(xx), '\n')
cat('Вектор хx больше не содержит выбросов \n')
cat('Создан дубль исходного вектора xout с выбросами \n')
cat('-------------------------\n')
}
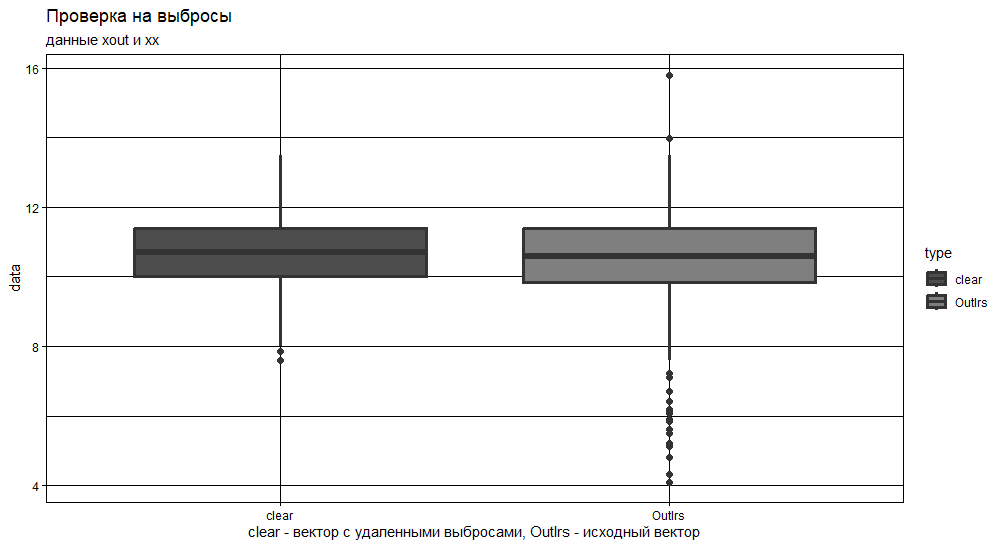
df = rbind(data.frame(type='Outlrs', data = xout),
data.frame(type='clear', data = xx))
#
BPpltGGP = function(df){
plot<-ggplot(df,
aes(x=type,y=data, fill=type)) +
geom_boxplot(lwd=1.1,outlier.size = 2)
# add scale_fill_manual function to specify colors
plot + scale_fill_manual(values = c("grey30","grey50", "grey70")) +
ggtitle("Проверка на выбросы ",
subtitle = "данные xout и хх") +
xlab("clear - вектор с удаленными выбросами, Outlrs - исходный вектор")+
theme_linedraw()
}
BPpltGGP(df)
# BPplt = function(df){
# boxplot(data~type,df)
# grid(col='grey40')
# boxplot(data~type,df, add=TRUE)
# }
# BPplt(df)
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
#
# 3) гистограмма с отклонениями по сигмам
#
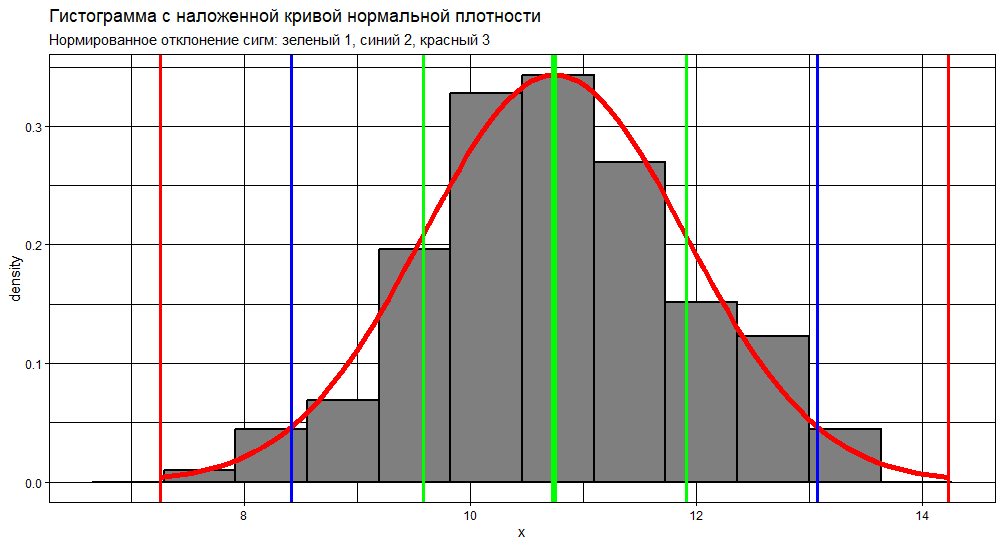
HpltGGP = function(x,bins){
# настройки:
Lsize = 1.3 #толщина линий нормир откл
Psize = 2 #толщина линии кривой норм плот распр
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
data = data.frame(x)
meanx = mean(x)
sdx = sd(x)
t = round((x - meanx)/sdx,1)
df = data.frame(x, t)
# граница значений плюс минус одна сигма
tmax1 = 1*sdx + meanx
tmin1 = meanx - 1*sdx
# граница значений плюс минус две сигм
tmax2 = 2*sdx + meanx
tmin2 = meanx - 2*sdx
# граница значений плюс минус три сигмы
tmax3 = 3*sdx + meanx
tmin3 = meanx - 3*sdx
ggplot(data, aes(x)) + # Draw histogram with density
geom_histogram(bins = bins,aes(y = ..density..), col='black', lwd =1, fill='grey50') +
stat_function(fun = dnorm,
args = list(mean = mean(data$x),
sd = sd(data$x)),
col = "red",
size = Psize) +
geom_vline(xintercept = tmin1, col='green', size = Lsize) +
geom_vline(xintercept = tmax1, col='green', size = Lsize) +
geom_vline(xintercept = meanx, col='green', size = (Lsize+1)) +
geom_vline(xintercept = tmin2, col='blue', size = Lsize) +
geom_vline(xintercept = tmax2, col='blue', size = Lsize) +
geom_vline(xintercept = tmin3, col='red', size = Lsize) +
geom_vline(xintercept = tmax3, col='red', size = Lsize) +
ggtitle("Гистограмма с наложенной кривой нормальной плотности",
subtitle = "Нормированное отклонение сигм: зеленый 1, синий 2, красный 3") +
theme_linedraw()
}
HpltGGP(x = xx,bins = 12 )
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
#
# 4) полная описательная статистика
# для данных в векторе x
#
options(scipen = 999, digits = 2) #отключить экспоненциальное представление в R
# функция AE расчета ассимметрии и эксеса
# ассимметрия skewness (AS) , эксес kurtosis (Ex)
AE = function(x, na.omit = F){
if (na.omit)
x = x[!is.na(x)]
m = mean(x)
med = median(x)
n = length(x)
s = sd(x)
skew = sum((x - m)^3/s^3)/n
kurt = sum((x - m)^4/s^4)/n - 3
minx = min(x)
maxx = max(x)
return(c(n = n, mean = m, median = med, SD = s,
As = skew, Ex = kurt, min = minx, max = maxx))
}
AE(xx)
# # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # # #
#
# 5) Тесты на нормальное распределение
# для данных в векторе xx
# p-value больше 0.05 H0 верна:
# данные в векторе подчиняются нормальному распределению
shapiro.test(xx)
#ks.test(xx, "pnorm")
# Load the nortest package for the Anderson-Darling test
library(nortest)
ad.test(xx)
# QQ test
qqnorm(xx)
qqline(xx, col='red', lwd=2)
# Автоматическое создание гистограммы с линиями Density, Normal:
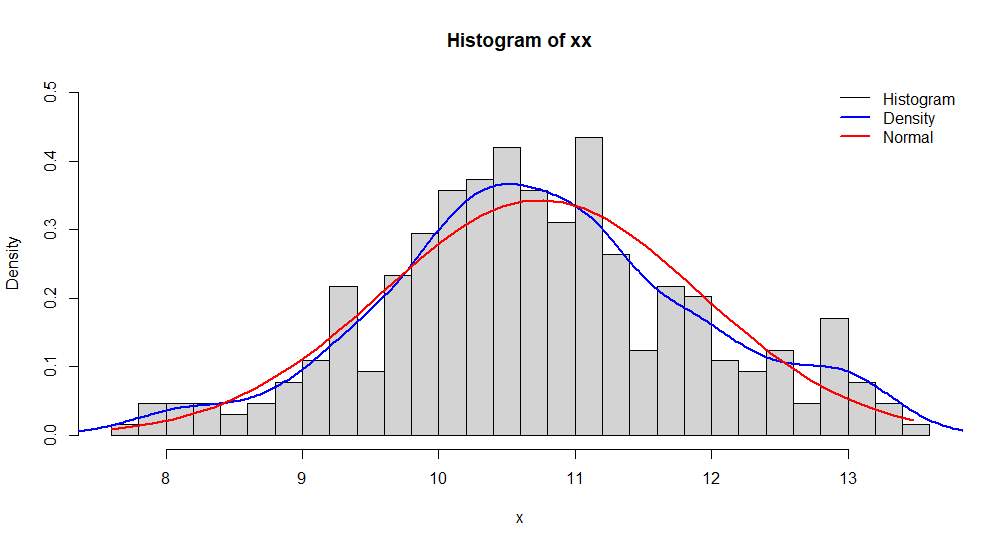
histDenNorm <- function (x,bins,ymax, main = "") {
hist(x, bins,prob = TRUE, main = main, ylim = c(0, ymax)) # Histogram
lines(density(x), col = "blue", lwd = 2) # Density
x2 <- seq(min(x), max(x), length = 40)
f <- dnorm(x2, mean(x), sd(x))
lines(x2, f, col = "red", lwd = 2) # Normal
legend("topright", c("Histogram", "Density", "Normal"), box.lty = 0,
lty = 1, col = c("black", "blue", "red"), lwd = c(1, 2, 2))
}
histDenNorm(x = xx,bins = 20,ymax = 0.06, main = "Histogram of xx")
# # # #