Анализ датасета данных юных спортсменов.
Для начала необходимо загрузить с нашего сайта файл архив sportkids с данными для этого жми сюда. Далее не забудем в скрипте указать путь к рабочей директории в которую разархивируем загруженный файл sportkids который представляет собой текстовый документ. По сути этот файл состоит из заголовков "Пол Рост Вес Пресс Прыжок" и целочисленных данных (обратим внимание что все данные разделены знаком "пробел" это важно учесть при чтении файла). Начало скрипта будет выглядеть следующим образом:
setwd('C:/datas')
kids=read.table('sportkids.txt',header=TRUE)
head(kids)
Поскольку первая строчка содержит названия колонок, то обязательно об этом "известим" среду программирования R: header=TRUE. Выполним конструкцию и выведем в консоль первые шесть строк (по умолчанию). Но можно немного изменить параметр и вывести например первые десять строк. head(kids,n = 10)
> head(kids,n = 10) Пол Рост Вес Пресс Прыжок 1 f 139 31 24 141 2 f 136 29 31 140 3 m 141 35 29 145 4 m 140 33 26 135 5 f 132 31 26 109 6 m 132 31 31 101 7 m 138 34 26 131 8 f 138 34 25 140 9 f 144 34 24 135 10 m 132 27 16 141 |
Изучим данные полученные из файла sportkids: выясним структуру и типы данных
str(kids) #Выводит полную структуру объекта
class(kids) #проверить тип данных "data.frame"
> str(kids) #Выводит полную структуру объекта 'data.frame': 40 obs. of 5 variables: $ Пол : chr "f" "f" "m" "m" ... $ Рост : int 139 136 141 140 132 132 138 138 144 132 ... $ Вес : int 31 29 35 33 31 31 34 34 34 27 ... $ Пресс : int 24 31 29 26 26 31 26 25 24 16 ... $ Прыжок: int 141 140 145 135 109 101 131 140 135 141 ... > str(kids) #Выводит полную структуру объекта 'data.frame': 40 obs. of 5 variables: $ Пол : chr "f" "f" "m" "m" ... $ Рост : int 139 136 141 140 132 132 138 138 144 132 ... $ Вес : int 31 29 35 33 31 31 34 34 34 27 ... $ Пресс : int 24 31 29 26 26 31 26 25 24 16 ... $ Прыжок: int 141 140 145 135 109 101 131 140 135 141 ... > class(kids) #проверить тип данных "data.frame" [1] "data.frame" |
А теперь приступим к первичному анализу данных. Для начала создадим два вектора которые будут содержать данные отдельно по двум группам ("f" и "m" это сокращения female (девочки) и мальчики male). Для этого выполним следующую конструкцию:
boys = kids[kids$Пол=='m',]
gerls = kids[kids$Пол=='f',]
Наглядно видно что у нас файл данных содержит данные о 19 мальчиках и 21 девочек. Теперь можно поработать с этими данными. Допустим мы хотим выбрать юных спортсменов у которых прыжок дальше 135 сантиметрам, для этого просто выполним следующую конструкцию:
# выбрать юных спортсменов у которых прыжок дальше 135
s = kids[kids$Прыжок > 135,]
s
> # выбрать юных спортсменов у которых прыжок дальше 135 > s = kids[kids$Прыжок > 135,] > s Пол Рост Вес Пресс Прыжок 1 f 139 31 24 141 2 f 136 29 31 140 3 m 141 35 29 145 8 f 138 34 25 140 10 m 132 27 16 141 13 f 136 31 22 150 14 f 138 35 21 139 15 f 137 33 31 155 24 f 139 35 29 150 25 m 145 38 26 141 26 f 136 31 21 157 27 m 136 30 24 145 33 m 144 33 28 145 36 m 144 37 32 144 39 f 140 40 37 141 40 m 146 42 34 151 |
Не совсем наглядно представлены данные: давайте разместим данные по длине прыжка в порядке возрастания от наименьшего значения к наибольшему, для этого выполним конструкцию:
s1 = s[order(s$Прыжок),]
s1
> s1 = s[order(s$Прыжок),] > s1 Пол Рост Вес Пресс Прыжок 14 f 138 35 21 139 2 f 136 29 31 140 8 f 138 34 25 140 1 f 139 31 24 141 10 m 132 27 16 141 25 m 145 38 26 141 39 f 140 40 37 141 36 m 144 37 32 144 3 m 141 35 29 145 27 m 136 30 24 145 33 m 144 33 28 145 13 f 136 31 22 150 24 f 139 35 29 150 40 m 146 42 34 151 15 f 137 33 31 155 26 f 136 31 21 157 |
Так же можно задавать и более сложные условия отбора. Например нам нужно отобрать девочек у которых прыжок дальше 130 сантиметров и рост выше 136 сантиметров. Выполним конструкцию:
# выбрать девочек у которых прыжок дальше 130 и рост выше 136
kids[kids$Прыжок > 130 & kids$Пол == 'f' & kids$Рост > 136,]
> # выбрать девочек у которых прыжок дальше 130 и рост выше 136 > kids[kids$Прыжок > 130 & kids$Пол == 'f' & kids$Рост > 136,] Пол Рост Вес Пресс Прыжок 1 f 139 31 24 141 8 f 138 34 25 140 9 f 144 34 24 135 14 f 138 35 21 139 15 f 137 33 31 155 24 f 139 35 29 150 39 f 140 40 37 141 |
Теперь выясним есть ли статистически значимые различия между средними показателями дальности прыжка у мальчиков и девочек. Выполним конструкцию (обратите внимание что эти две строки будут давать один и тот же результат, первая конструкция выглядит грамозко и не уклюже, но к счастью можно провести тот же самый тест воспользовавшись разделением на группы. Так же обратите внимание что на этот раз мы работаем со всеми представленными данными по весу):

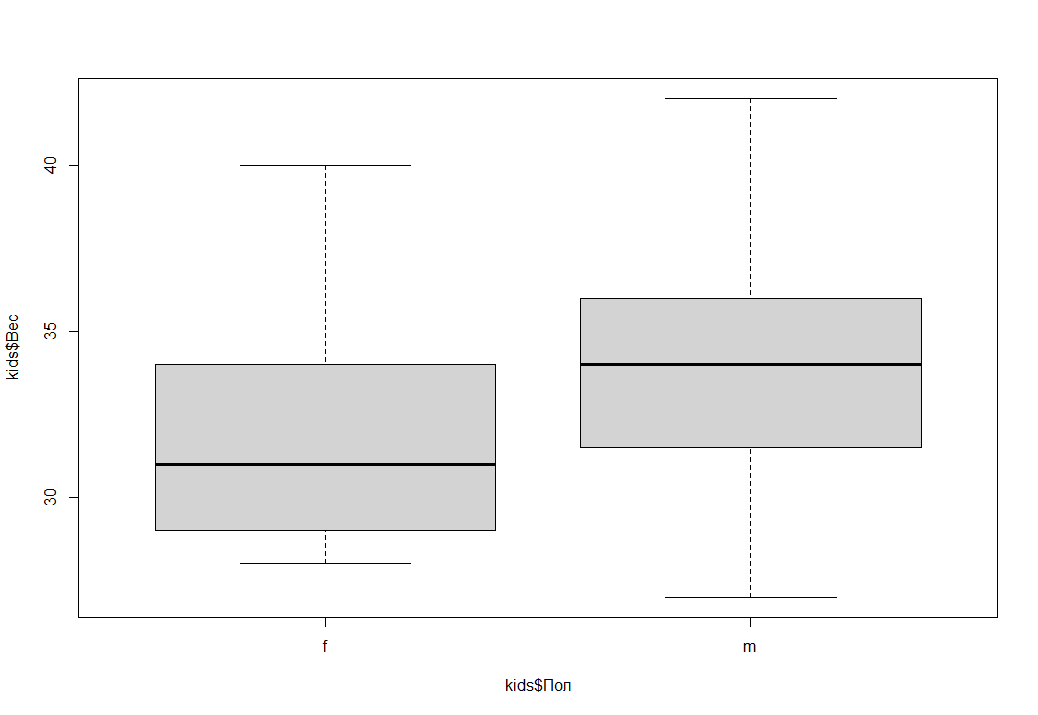
Построим для большей наглядности "ящик с усами" который отразит графически некоторые описательные статистики по весу среди девочек и мальчиков. Для чего выполним простую конструкцию (и далее выполним Welch Two Sample t-test):
boxplot(kids$Вес ~ kids$Пол)
Так же можно воспользоваться функцией StatTwoGrupCI (загрузить ее можно с нашего сайта жми сюда):
setwd('C:/R myFunction')
source('StatTwoGrupCI.R')
StatTwoGrupCI(x1 = boys$Вес, x2 = gerls$Вес, CI = 97)
> StatTwoGrupCI(x1 = boys$Вес, x2 = gerls$Вес, CI = 97) ----------------------------------------------------- Name N Mean SD Med As Ex Min Max V CS 1 X1 19 33.94737 3.778208 34 0.06203894 -0.56948724 27 42 11.12960 2.553306 2 X2 21 31.66667 3.336665 31 0.86967538 -0.07377375 28 40 10.53684 2.299326 ----------------------------------------------------- Name Low Hi 1 X1 31.90508 35.98966 2 X2 29.96560 33.36773 ----------------------------------------------------- Welch Two Sample t-test data: x1 and x2 t = 2.0147, df = 36.161, p-value = 0.05142 alternative hypothesis: true difference in means is not equal to 0 97 percent confidence interval: -0.2766602 4.8380638 sample estimates: mean of x mean of y 33.94737 31.66667 |
t.test(kids[kids$Пол=='m',]$Вес , kids[kids$Пол=='f',]$Вес)
t.test(kids$Вес ~ kids$Пол)
> t.test(kids$Вес ~ kids$Пол) Welch Two Sample t-test data: kids$Вес by kids$Пол t = -2.0147, df = 36.161, p-value = 0.05142 alternative hypothesis: true difference in means between group f and group m is not equal to 0 95 percent confidence interval: -4.57618789 0.01478438 sample estimates: mean in group f mean in group m 31.66667 33.94737 |
p-value = 0.05142 что немного превышает уровень 0.05, что с одной стороны говорит о принятии нулевой гипотезы о равенстве групп, то есть среднее значение по массе у юных спортсменов одинаковы или проще говоря средний вес мальчиков и девочек является одинаковым а отличия носят случайный характер. Но с другой стороны лучше провести еще дополнительные исследования (то есть обработать больше данных). Или на худой случай (если нет такой возможности) провести бутстреп анализ не забудем так же загрузить с нашего сайта функцию CIboot и поместить ее в рабочую директорию
setwd('C:/R myFunction')
source('CIboot.R')
CIboot(x1 = kids[kids$Пол=='m',]$Вес,
x2 = kids[kids$Пол=='f',]$Вес,R = 1000, CI = 98
> CIboot(x1 = kids[kids$Пол=='m',]$Вес, x2 = kids[kids$Пол=='f',]$Вес,R = 1000, CI = 98) Welch Two Sample t-test data: x1 and x2 t = 2.0147, df = 36.161, p-value = 0.05142 alternative hypothesis: true difference in means is not equal to 0 95 percent confidence interval: -0.01478438 4.57618789 sample estimates: mean of x mean of y 33.94737 31.66667 ConfLevel_x1 ConfLevel_x2 1 0.98000 0.98000 2 31.91552 30.05631 3 35.88069 33.29979 |
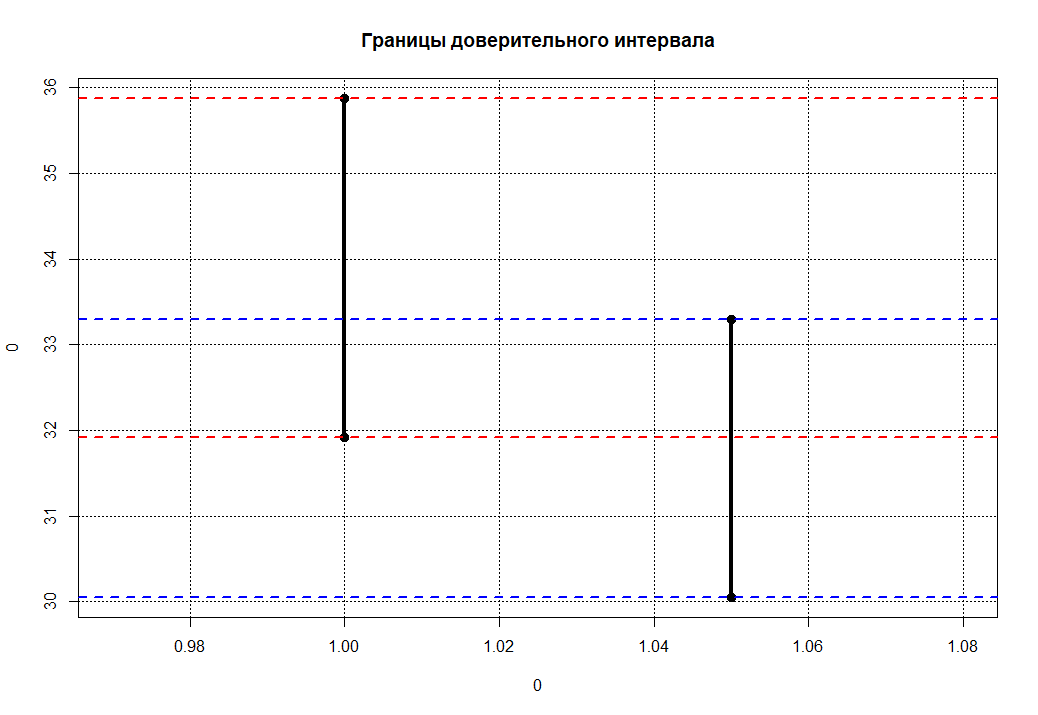
Как мы наглядно убедились и с использованием бутстрепа: статистически значимых различий в группах нет.
А теперь давайте выясним есть ли зависимость у мальчиков дальности прыжка от их веса. Сначала отберем нужные нам данные (предлагаю два способа - они дают одинаковый результат, но второй более наглядный так как отражает какие данные подверглись отбору)
SM = boys[,c(3,5)]
SM = boys[,c('Вес', 'Прыжок')]
SM
> SM Вес Прыжок 3 35 145 4 33 135 6 31 101 7 34 131 10 27 141 12 39 129 16 35 135 17 34 130 19 36 129 20 35 134 23 28 131 25 38 141 27 30 145 30 30 115 31 32 120 33 33 145 36 37 144 38 36 132 40 42 151 |
cor(SM$Вес, SM$Прыжок)
> cor(SM$Вес, SM$Прыжок) [1] 0.346910 |
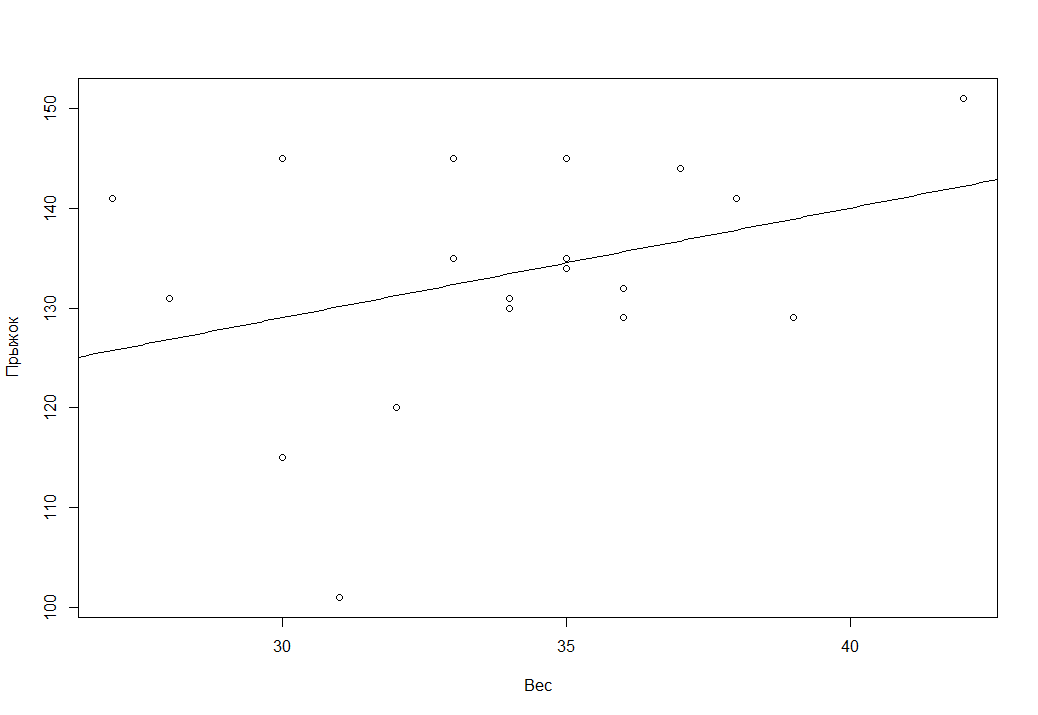
Видим что зависимость очень небольшая, попробуем это предствить еще более наглядно с помощью точечного графика
plot(SM)
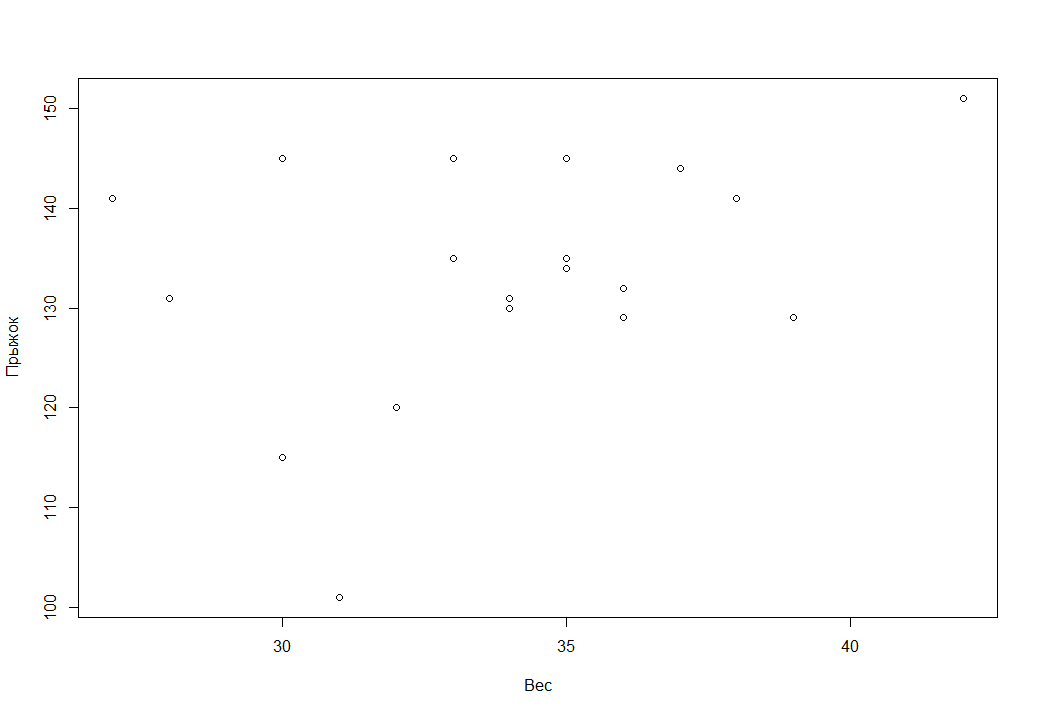
И все же попробуем найти уравнение регрессии зависимости дальности прыжка от веса юного спортсмена
bsm = lm(SM$Прыжок ~ SM$Вес )
summary(bsm)
xx = seq(25, 45, 0.1)
yy = 1.0989*xx + 96.0625
lines(xx,yy)
> summary(bsm) Call: lm(formula = SM$Прыжок ~ SM$Вес) Residuals: Min 1Q Median 3Q Max -29.1295 -5.1241 0.4748 8.0296 15.9695 Coefficients: Estimate Std. Error t value Pr(>|t|) (Intercept) 96.0625 24.6051 3.904 0.00114 ** SM$Вес 1.0989 0.7206 1.525 0.14563 --- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 11.55 on 17 degrees of freedom Multiple R-squared: 0.1203, Adjusted R-squared: 0.0686 F-statistic: 2.326 on 1 and 17 DF, p-value: 0.1456 |