Сравнение Генеральной Совокупности с ее моделью созданной из малой выборки
На нашей сайте уже был разговор о создании генеральной совокупности из малой выборки, продолжаем развивать эту тему. И сегодня поставим задачу сравнить между собой реальную ГС с искусственно созданной из выборки небольшого размера. Для начала загрузите с нашего сайта скрипт функции MinInGS и на диске С создайте папку R myFunction куда и сохраните скачанный файл. В скрипте укажем путь к этому файлу:
setwd('C:/R myFunction')
source('MinInGS.R')
Вот теперь мы готовы выполнить задачу сравнить между собой реальную ГС с искусственно созданной из выборки небольшого размера. План наших действий:
- Создаем реальную генеральную совокупность GSr объемом 2000 элементов
- Случайным образом извлекаем из нее 50 элементов и образуем выборку x малого размера
- Из выборки в 50 элементов с помощью разработанной функции создадим искусственную генеральную совокупность точно такого же объема, как и исходная (в нашем случае из 2000 элементов)
- Проведем статистический тест между двумя выборками GSr и GS
set.seed(454)
GSr = rnorm(2000, 100, 3) # GSr = реальная ГС
# выбираем из GSr случайно size = 300 элементов
# образуя выборку элементов исходящих из GSr
x = sample(GSr, size = 50, replace = F)
MinInGS(data = x, N = 2000, cl = 0.99)
summary(GSr)
summary(GS)
sd(GSr)
sd(GS)
t.test(GSr, GS,conf.level = 0.98)
> summary(GSr) Min. 1st Qu. Median Mean 3rd Qu. Max. 88.57 97.91 99.97 99.91 101.95 109.56 > summary(GS) Min. 1st Qu. Median Mean 3rd Qu. Max. 92.24 98.25 100.00 100.09 101.82 109.00 > sd(GSr) [1] 2.983601 > sd(GS) [1] 2.630865 > t.test(GSr, GS,conf.level = 0.98) Welch Two Sample t-test data: GSr and GS t = -2.0022, df = 3936.3, p-value = 0.04533 alternative hypothesis: true difference in means is not equal to 0 98 percent confidence interval: -0.38509662 0.02891777 sample estimates: mean of x mean of y 99.9105 100.0886 |
Было получено p-value = 0.04533 (на самом деле это значение может принимать различные случайные значения, так как предсказать точно какие именно данные попадут в бутстреп анализ невозможно). Но значение p-value = 0.04533 меньше критического 0.05 поэтому можно поставить под сомнение нулевую гипотезу о равенстве исследуемых ГС. Поэтому имеет смысл провести не одно а скажем 500 таких испытаний (ну чем вам не снова бутстреп) и выяснить сколько процентов от всех полученных искусственно ГС статистически не отличаются от реальной ГС.
SIZE = 500
N = 2000
ttest = c()
for (k in 1:N) {
x1 = sample(GSr, size = SIZE, replace = F)
x2 = sample(GS, size = SIZE, replace = F)
tt=t.test(x1, x2)
ttest = c(ttest,tt$p.value)
}
hist(ttest)
neg = length(ttest[ttest<0.05])
cat('испытаний:', N, 'не прошло тест', round(neg/N*100,1),'%')
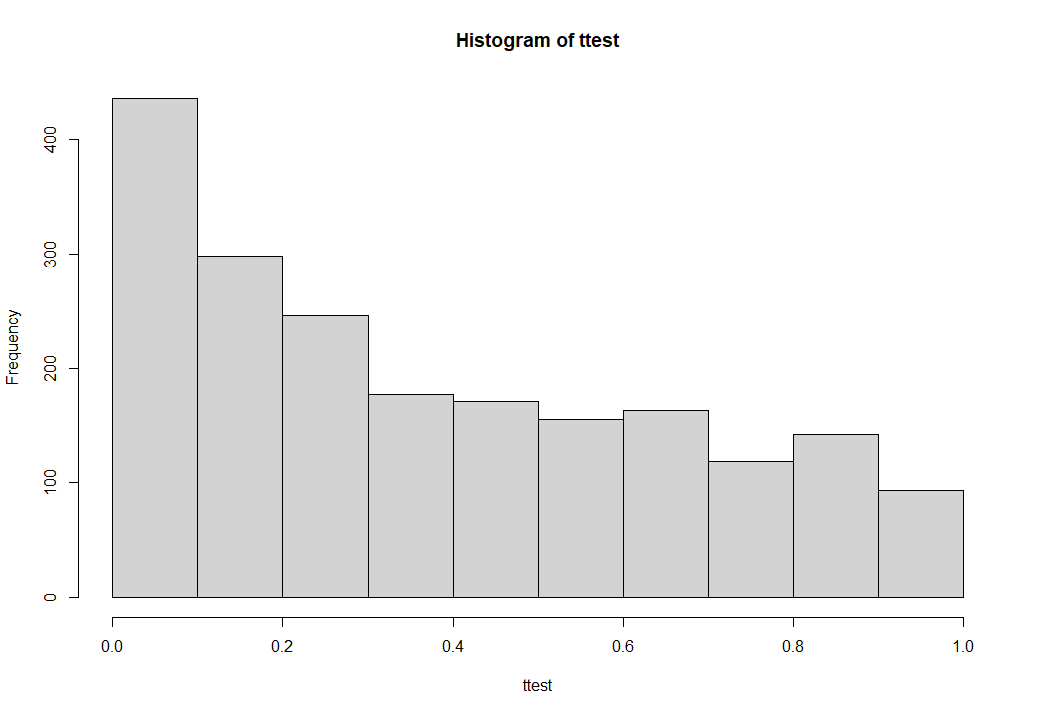
Выполнив конструкцию, получаем «испытаний: 2000 не прошло тест 12.8 %». Но нас интересуют как раз положительный исход, то есть, когда мы не отклоняем нулевую гипотезу это примерно 87 процентов от общего результата. Ставим новую задачу: написать конструкцию, которая будет создавать новые искусственные генеральные совокупности и сравнивать их до тех пор, пока критическое значение не превысит некий заданный порог. Это можно легко реализовать, применив в конструкции цикл с условием
tt2=0.0
while (tt2 < 0.98) {
MinInGS(data = x, N = 2000, cl = 0.99)
# summary(GSr)
# summary(GS)
# sd(GSr)
# sd(GS)
tt1=t.test(GSr, GS,conf.level = 0.97)
tt2 = tt1$p.value
}
tt2
hist(GSr, freq = F, ylim = c(0, 0.15))
lines(density(GSr), lwd = 2, col='blue')
lines(density(GS), lwd = 2, col='red')
grid(col='grey50')
t.test(GSr, GS,conf.level = 0.97)
Выполнив конструкцию, получаем «испытаний: 2000 не прошло тест 12.8 %». Но нас интересуют как раз положительный исход, то есть, когда мы не отклоняем нулевую гипотезу это примерно 87 процентов от общего результата. Ставим новую задачу: написать конструкцию, которая будет создавать новые искусственные генеральные совокупности и сравнивать их до тех пор, пока критическое значение не превысит некий заданный порог. Это можно легко реализовать, применив в конструкции цикл с условием
tt2=0.0
while (tt2 < 0.97) {
MinInGS(data = x, N = 2000, cl = 0.99)
# summary(GSr)
# summary(GS)
# sd(GSr)
# sd(GS)
tt1=t.test(GSr, GS,conf.level = 0.97)
tt2 = tt1$p.value
}
tt2
hist(GSr, freq = F, ylim = c(0, 0.15))
lines(density(GSr), lwd = 2, col='blue')
lines(density(GS), lwd = 2, col='red')
grid(col='grey50')
t.test(GSr, GS,conf.level = 0.97)
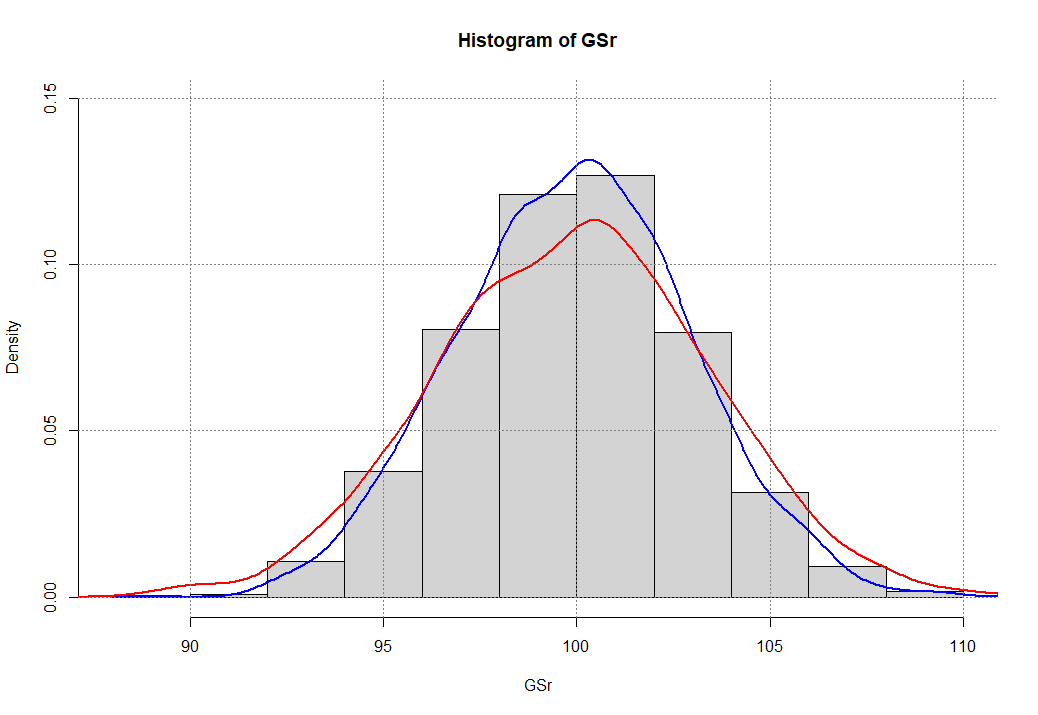
> tt2 [1] 0.9916289 > hist(GSr, freq = F, ylim = c(0, 0.15)) > lines(density(GSr), lwd = 2, col='blue') > lines(density(GS), lwd = 2, col='red') > grid(col='grey50') > t.test(GSr, GS,conf.level = 0.97) Welch Two Sample t-test data: GSr and GS t = 0.010492, df = 3898.5, p-value = 0.9916 alternative hypothesis: true difference in means is not equal to 0 97 percent confidence interval: -0.2223671 0.2245271 sample estimates: mean of x mean of y 99.91050 99.90942 |
Как видите мы получили вполне неплохой результат, хотя иногда придется подождать пока удача (в нашем случае сравниваемое критическое значение между двумя генеральными выборками достигнут 0.97) постучится: цикл завершит свою работу и можно будет завершить анализ (представив его для наглядности в графическом виде). Пару замечаний чтобы сократить время ожидания (особенно если у вас слабый компьютер): выборку сократите до n = 30, уровень значимости для начала установите 0.95. А далее уже экспериментируйте с этими настройками на здоровье, все равно все у вас обязательно получиться.